多模态文档处理预训练任务
date
Jun 7, 2022
slug
多模态文档处理预训练任务
status
Published
tags
Computer Vision
OCR
Deep Learning
summary
虽然训不起,但还是要了解下
type
Post
LayoutLM
- Masked Visual-Language Model (MVLM):和 BERT 类似的 mask 方式,在输入的 text token 中随机筛选 15% 的 token,其中 80% 替换为 [MASK],10% 替换为随机的 token,10% 不变 ,使用交叉熵损失训练,预测筛选出来的 token 是哪个词。
- Multi-label Document Classification(MDC):利用 IIT-CDIP 数据集的多分类标签进行监督训练。
LayoutLMv2
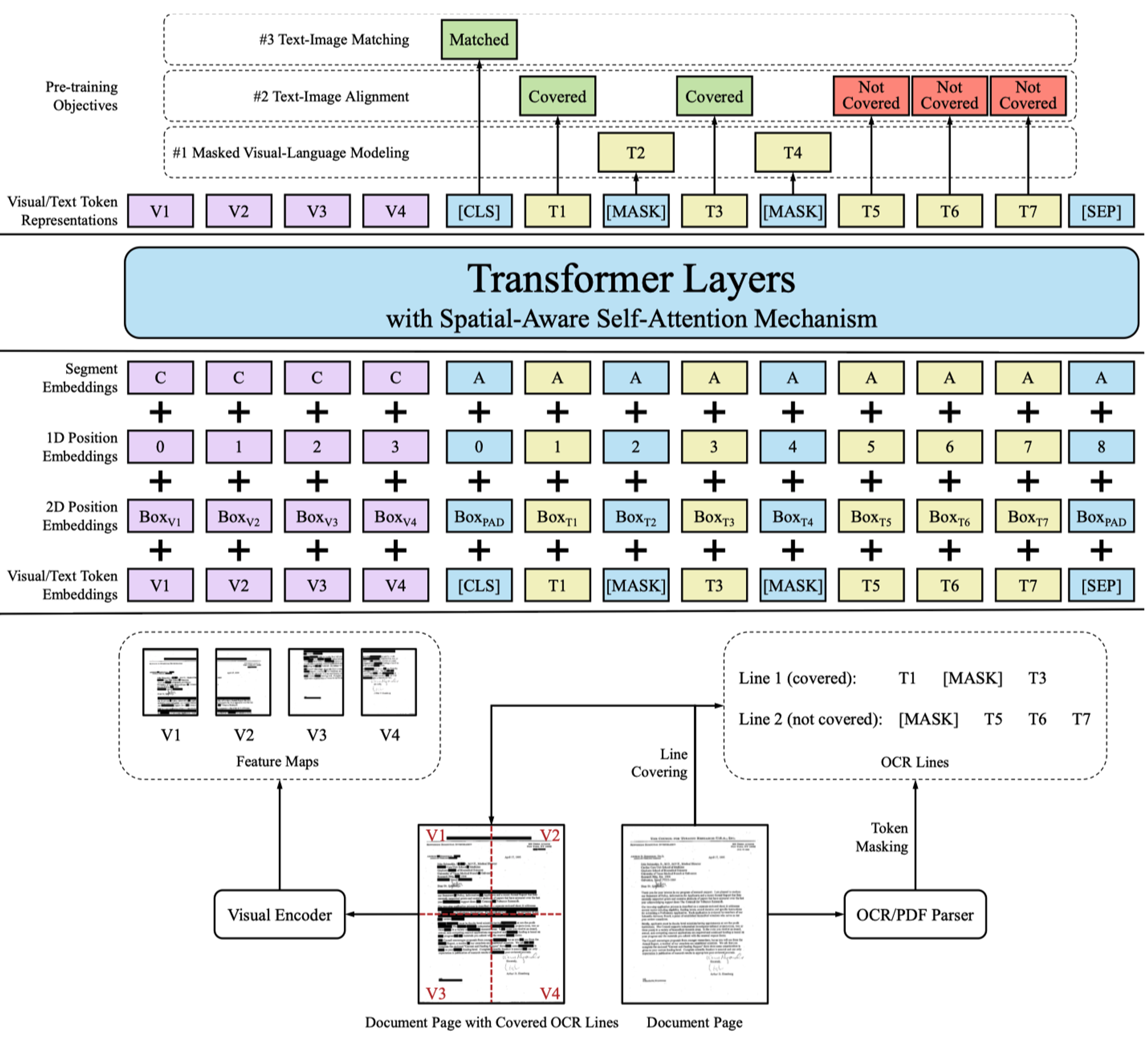
- Masked Visual-Language Model (MVLM):和 LayoutLM 一样的 mask 策略,不同点在于会将 masked text token 所对应的图像区域也进行 mask。
- Text-Image Alignment (TIA):随机筛选一些 text tokens,把原图上对应的区域覆盖掉(Covered),使用 BCE 计算每个 text token 是否被覆盖了。
- Text-Image Matching (TIM):图片和文档内容是否匹配,[CLS] token 接一个单独的二分类头,使用 BCE 计算损失。
LayoutLMv3
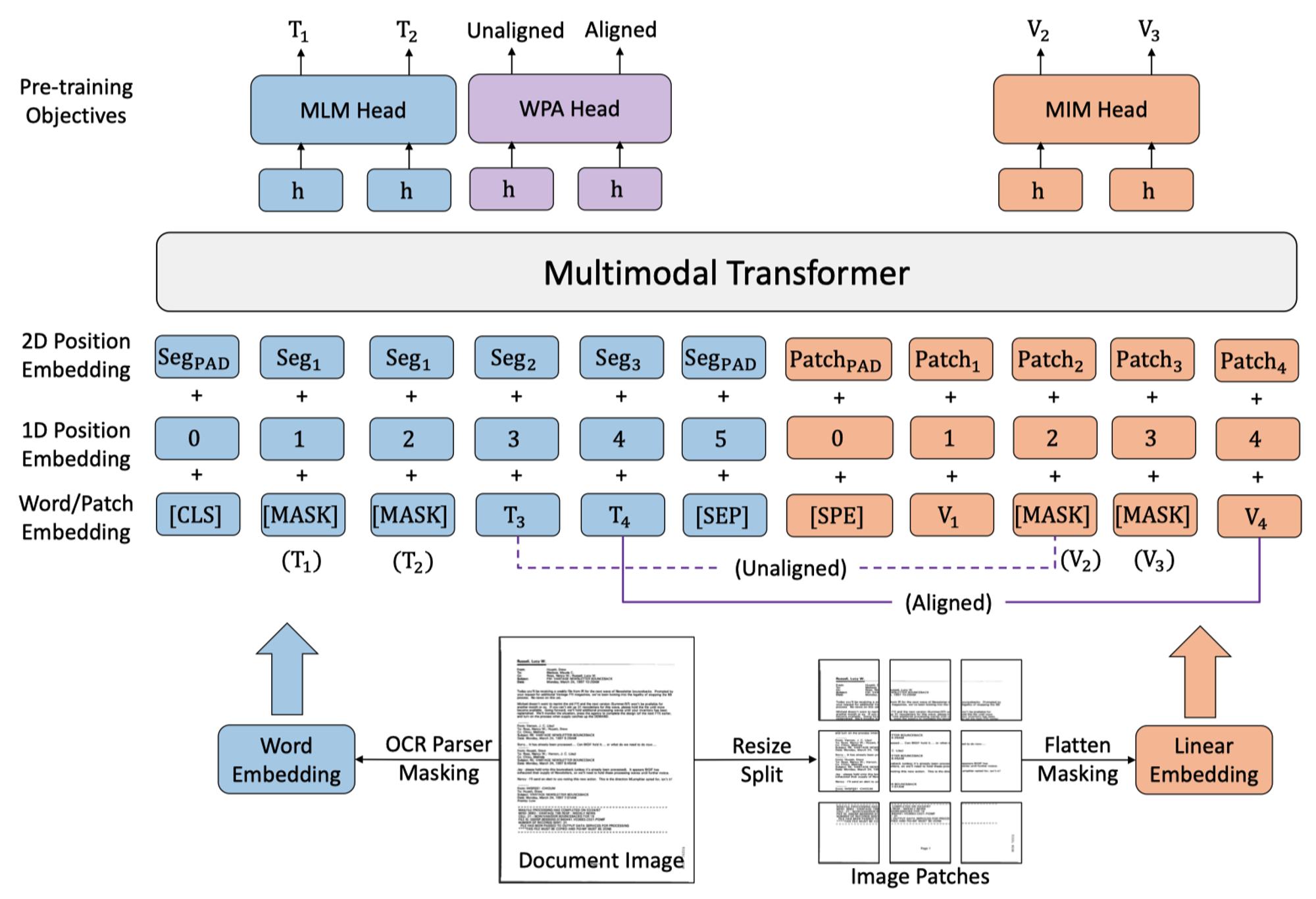
- Masked Language Modeling (MLM):和 LayoutLMv2 一样,但是 mask 的策略改变了。
Mask 30% of text tokens with a span masking strategy with span lengths drawn from a Poisson distribution (λ = 3) [20, 24].
- Masked Image Modeling (MIM):使用 Zero-Shot Text-to-Image Generation 中的 image tokenizer 来获得 image token(32x32,vocab_size=8192),对 image token 进行 mask,用交叉熵作为损失函数预测 masked token 的类别。
- Word-Patch Alignment (WPA):BCE 作为损失函数,显示地学习 text 和 image 的对齐关系,根据 text token 和对应的 image token 的 mask 状态获得分类标签。
text token | image token | label |
unmasked | unmasked | aligned |
unmasked | masked | unaligned |
masked | masked/unmasked | ignore |
StrucTexT
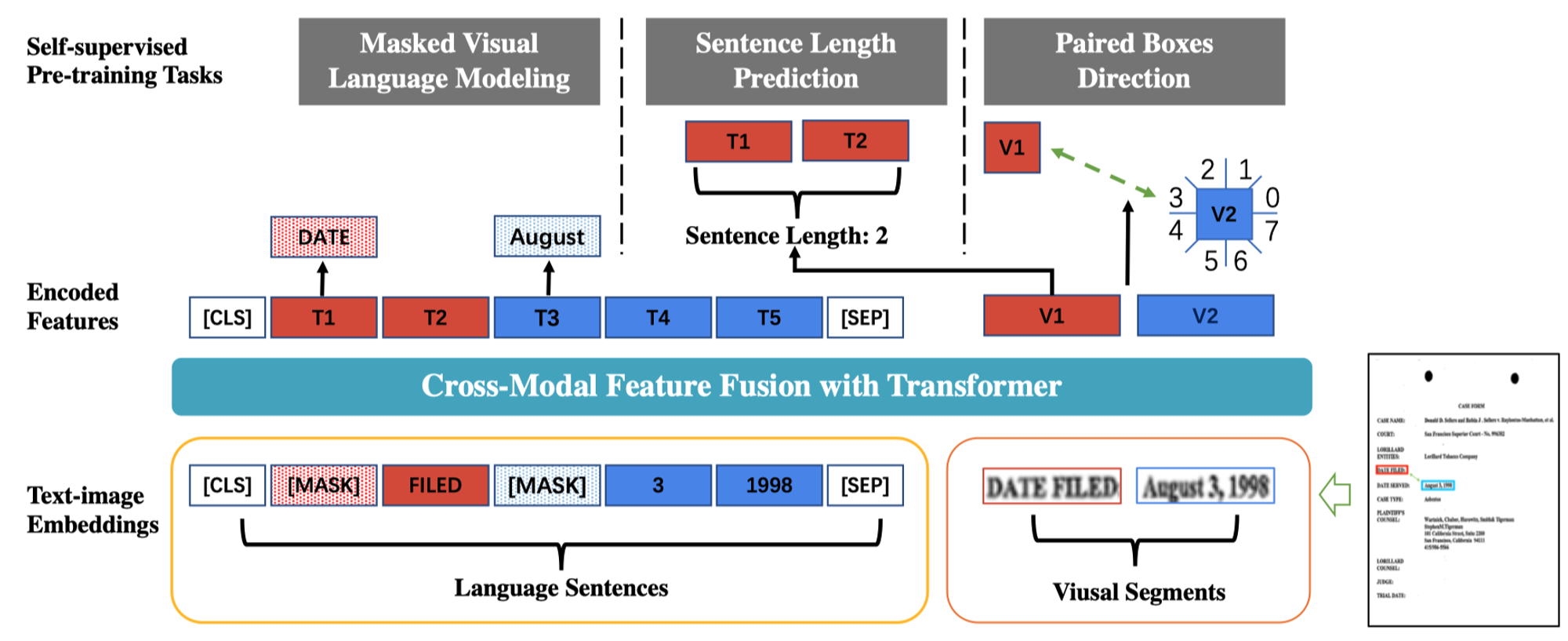
- Masked Visual Language Modeling (MVLM):和 LayoutLM 中的策略一致,不会对图片区域进行 mask。
- Sequence Length Prediction (SLP):取一组文本框,让模型根据视觉特征和文本特征(每个文本框的第一个 sub-word,也就是第一个 token?)学习一共有几个文本框,即上图中的 Sentence Length: 2,也是当做分类任务训练。
- Paired Boxes Direction (PBD):学习文本框之间的的相对位置关系,将位置关系表示为 8 个类别,当做分类任务训练。
LiLT
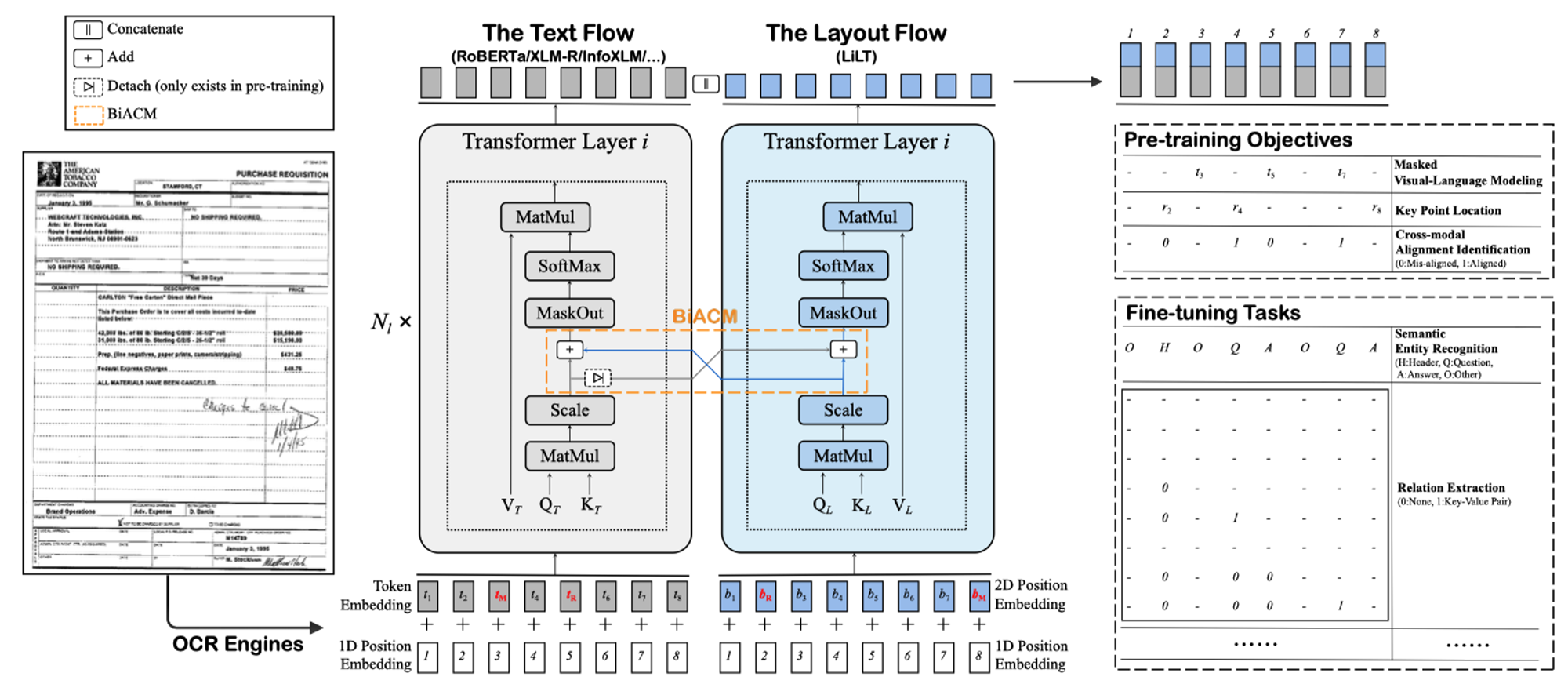
- Masked Visual Language Modeling (MVLM)
- Key Point Location (KPL):把图片平均分为 49 个区域,预测每个文本框的左上点、右下点和中心点在哪个区域,当做分类任务训练。
- Cross-modal Alignment Identification (CAI):从 MVLM 和 KPL 任务中收集 token-box 对,随机替换其中的某一项作为负样本,如果不替换则为增样本,当做二分类任务训练。