百度 EasyDL OCR 平台体验
date
Jan 20, 2022
slug
百度 EasyDL OCR 平台体验
status
Published
tags
Deep Learning
OCR
Platform
summary
有亿点点厉害
type
Post
在很多人眼里 OCR 或许是一门非常”古老”的技术,实际上它也确实很古老,早在上世纪 90 年代,最早的神经网络之一 LeNet 就是设计用来识别单个手写数字的,应用于美国邮政局,下面👇🏻是一段 LeNet 的演示 demo。

时至今日,OCR 这个概念已经变得越来越宽泛了,例如印章识别、合同文档比对、文档结构化信息抽取、表格还原等等,每一项任务都有不同的技术难度和业务特点。以文档结构化信息抽取为例,在银行、保险公司这类存在大量内部单据的公司,厂商提供的标准类型证件接口通常无法满足需求,虽然可以单独招标请厂商进行定制开发,但越来越多的客户和 OCR 厂商开始意识到,要解决 OCR 领域的长尾问题,更重要的是要有一个平台把厂商在 OCR 方面的专业能力和经验固化,对客户进行赋能(不知不觉就用了这个黑话。。),客户只要喂数据就能完成 OCR 需求的开发。百度推出的 EasyDL OCR 就是这样一个平台,以下是来自 EasyDL OCR 官网对其平台的描述:
定制识别图片中的文字信息,结构化输出关键字段内容,极大提升 OCR 模型训练效率,满足个性化卡证票据识别需求。
这次体验的整体流程如下:
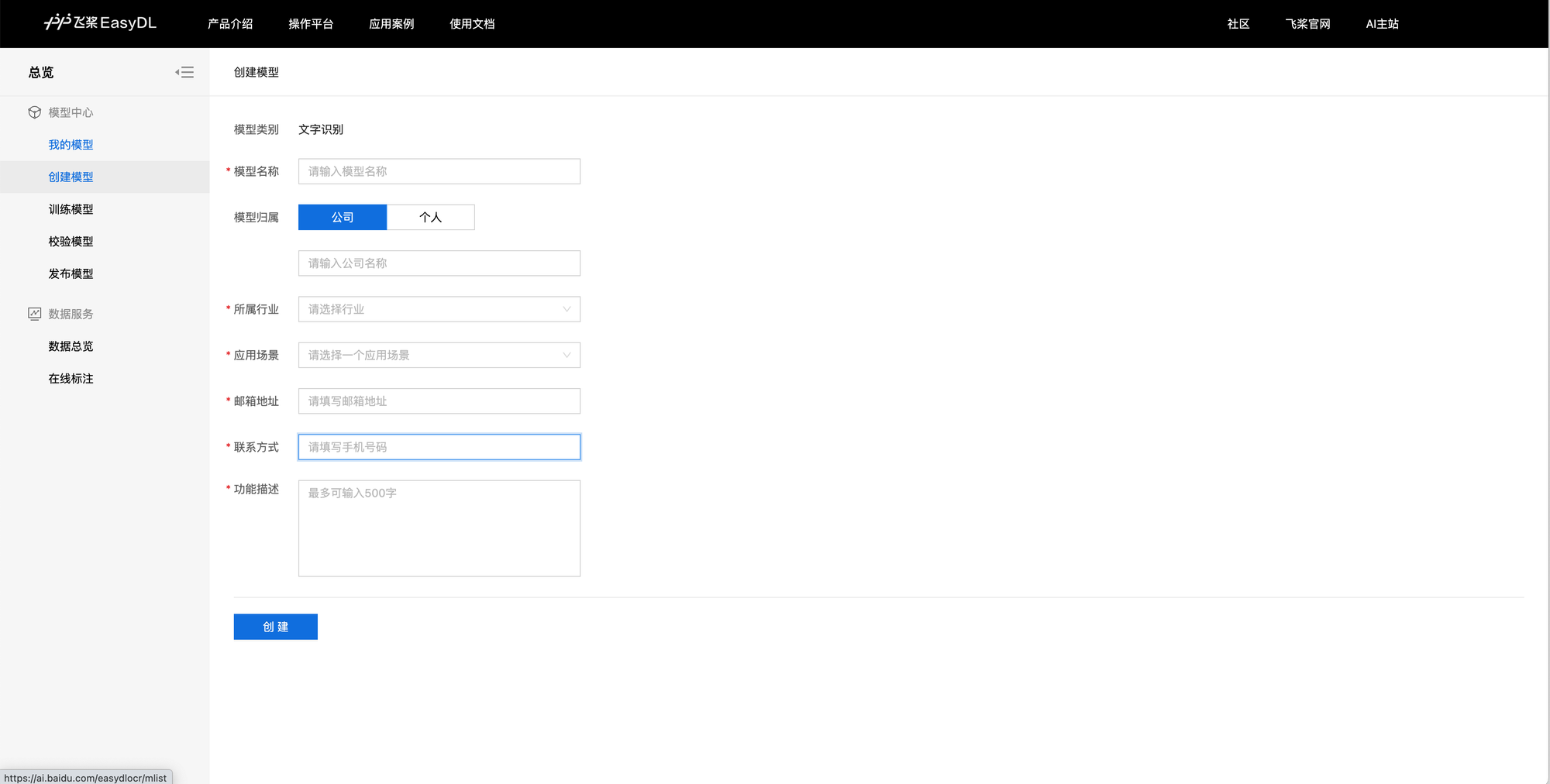
创建模型
官网上写了可以根据需求选择不同的模型类别,但在创建模型页面「模型类别」是没有选项的,固定为「文字识别」这一项,从后续的体验来看,这里的文字识别,并不是 CRNN 之类的文本识别模型,而是面向非专业人士的,对于基于图片的信息抽取任务的一个统称。
准备数据
这次体验用的数据为从 github trading 页面截取的屏幕截图,目标是提取每个项目的开发者和项目名称,例如下图的第一行,开发者名称是 ossu,项目名为 computer-science,第三行,开发者名是 2dust,项目名是 v2rayN。总共 30 张截图,每张包含 3 到 6 个项目不等。
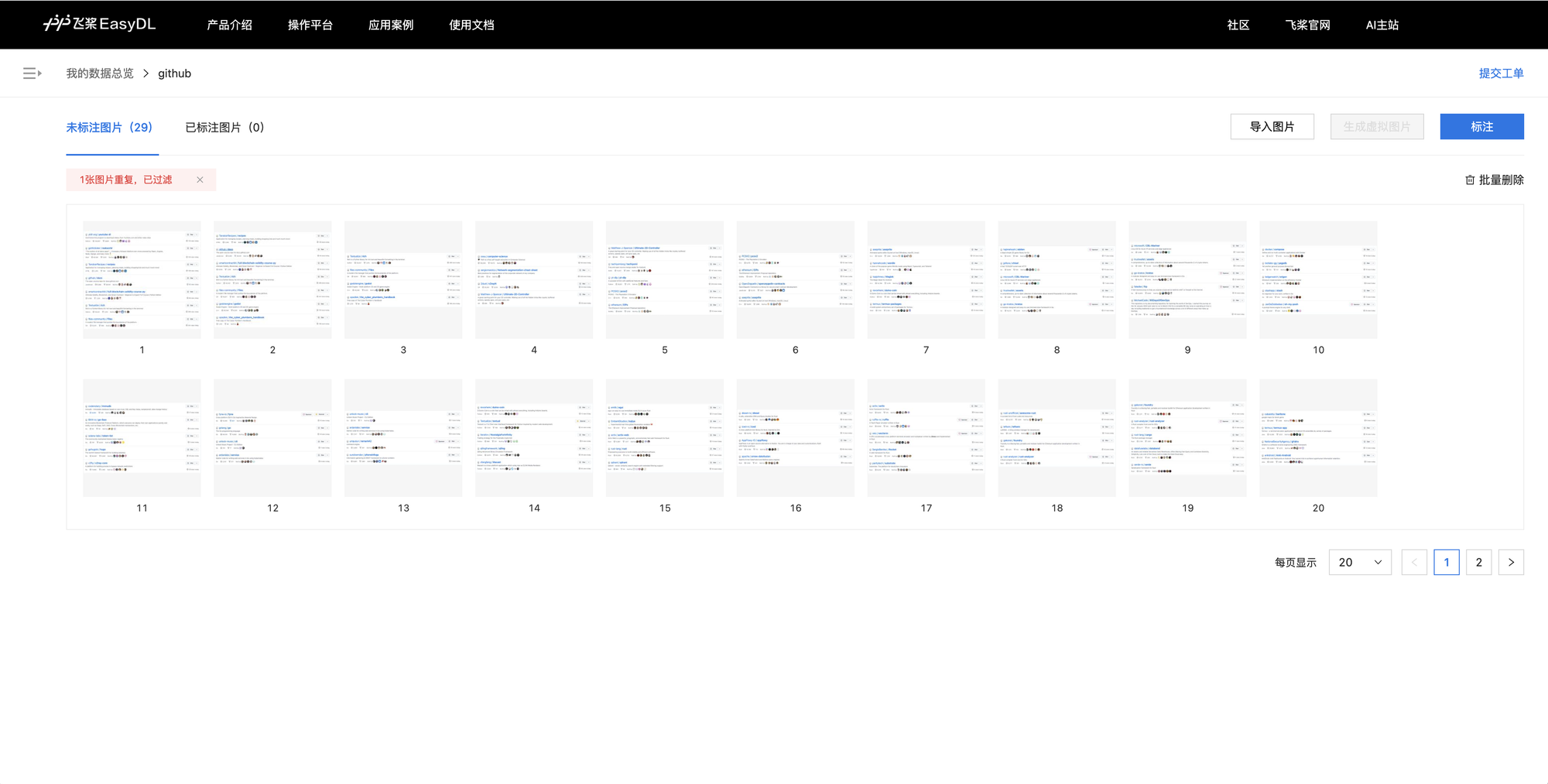
导入数据界面支持上传图片和压缩包,图片方式一次最多五张,效率较低,但是试了两次 zip 包方式上传数据都失败了,无奈只能分 6 次上传 30 张图片,上传过程中系统会过滤掉重复的图片,好评。
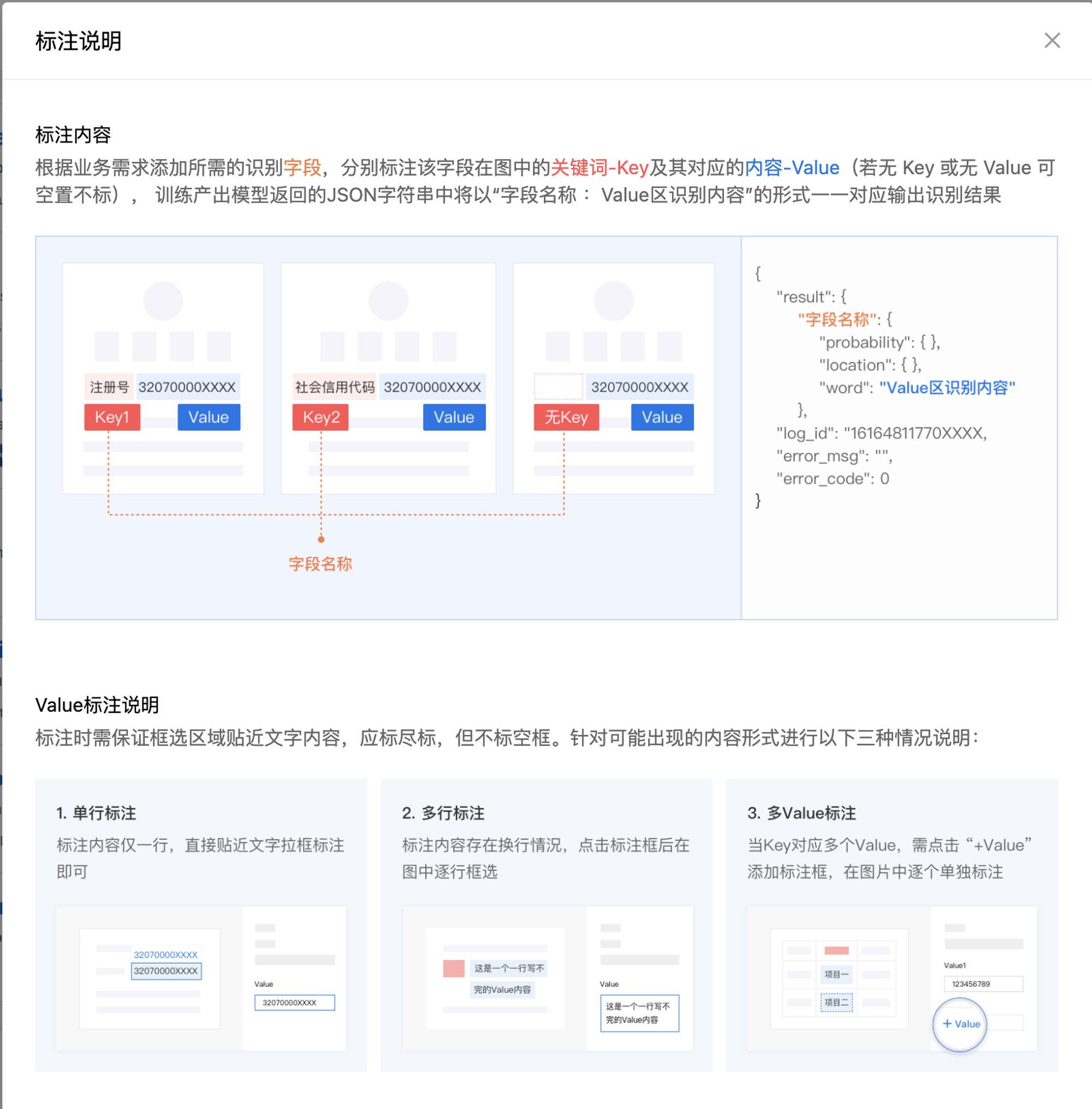
数据标注
标注页面的说明包含了多种可能的 key-value 布局情况,整体还是比较清晰明了的。
在右侧添加要提取的字段:开发者和项目名,然后开始标注。标识过程中,value 部分会自动填入框选范围内的内容,没看到有网络请求,应该是在 web 端做的轻量级识别模型,对于截图的识别准确率还不错,整个过程中只改了两三次识别结果,其中有一个项目名以 W 开头,无论怎么框选识别结果都是 N。图片上的标注框,不同字段的颜色是一样的,无法区分字段类型,只能通过标注框和右侧 value 内容的关联关系来确认其类型。
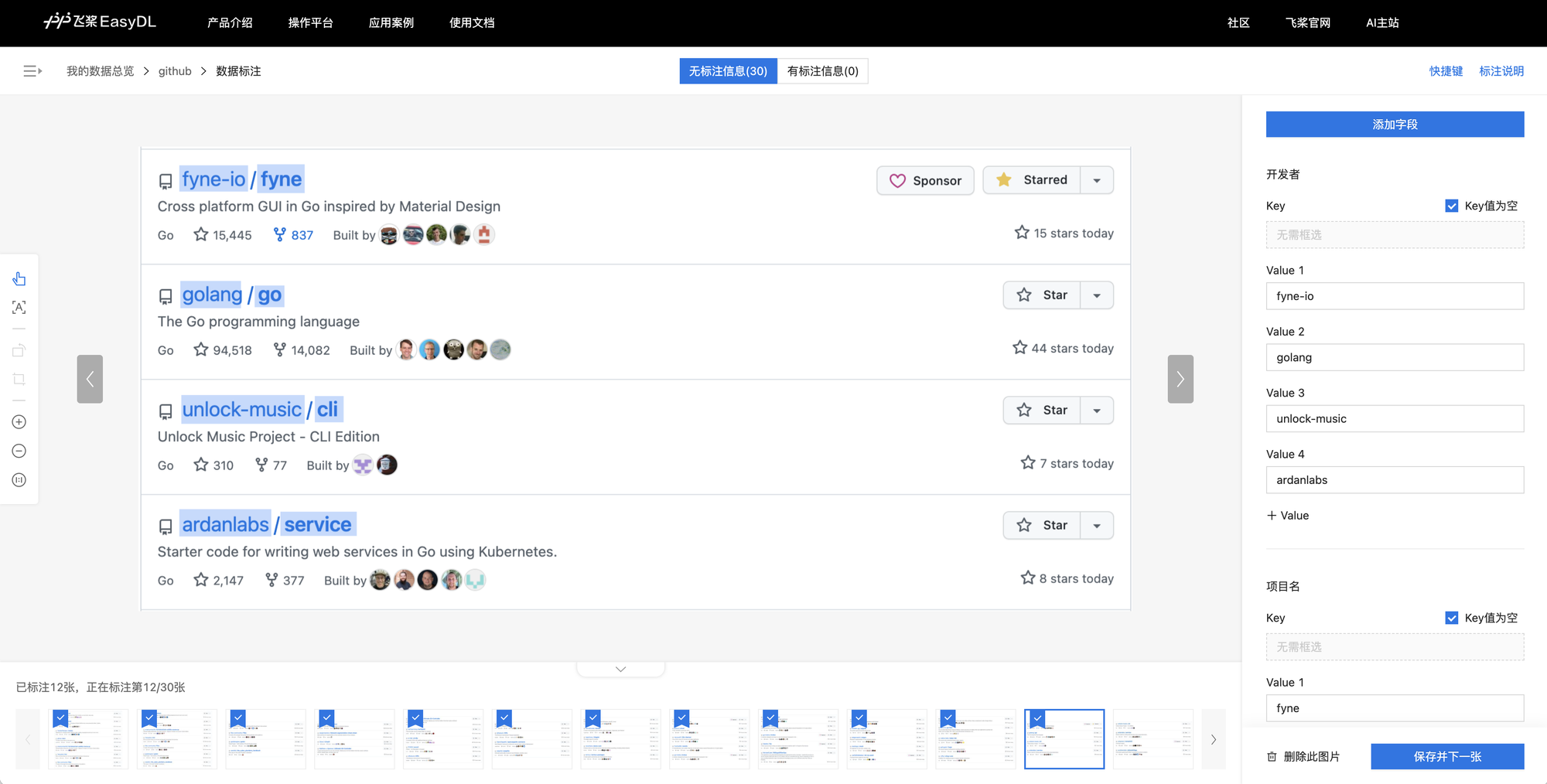
这些数据是用来训什么模型的?一般来说平台肯定都会预置文本检测、识别模型,30 张训练数据用于调优也是完全不够的,大概率是进行信息抽取模型的 fine tuning。
虚拟数据生成
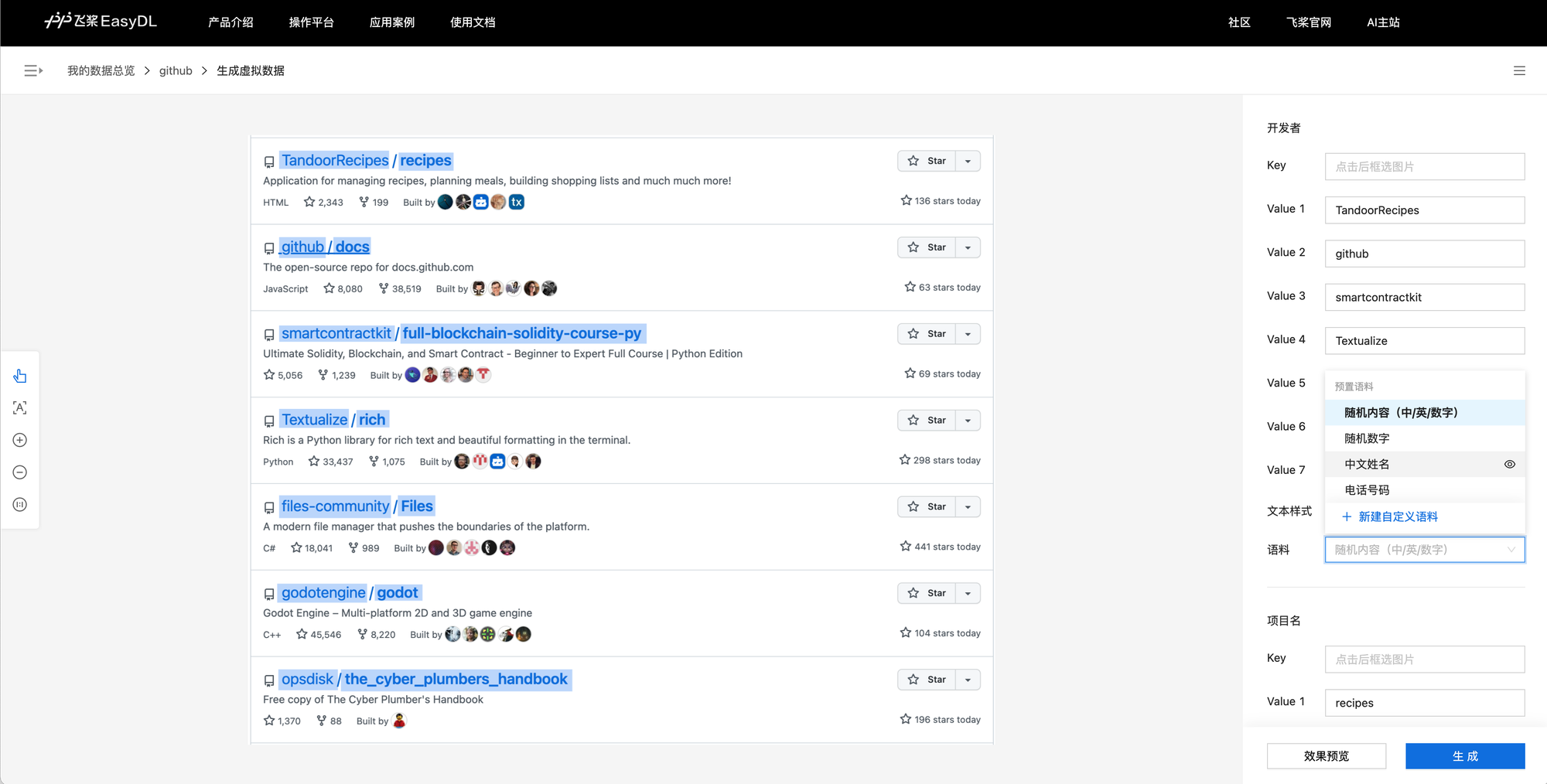
做 OCR 任务很重要的一步是数据生成,通过少量数据,以传统图像处理的方式替换图片上的文本,并添加各种扰动,提高模型的泛化性和准确率。
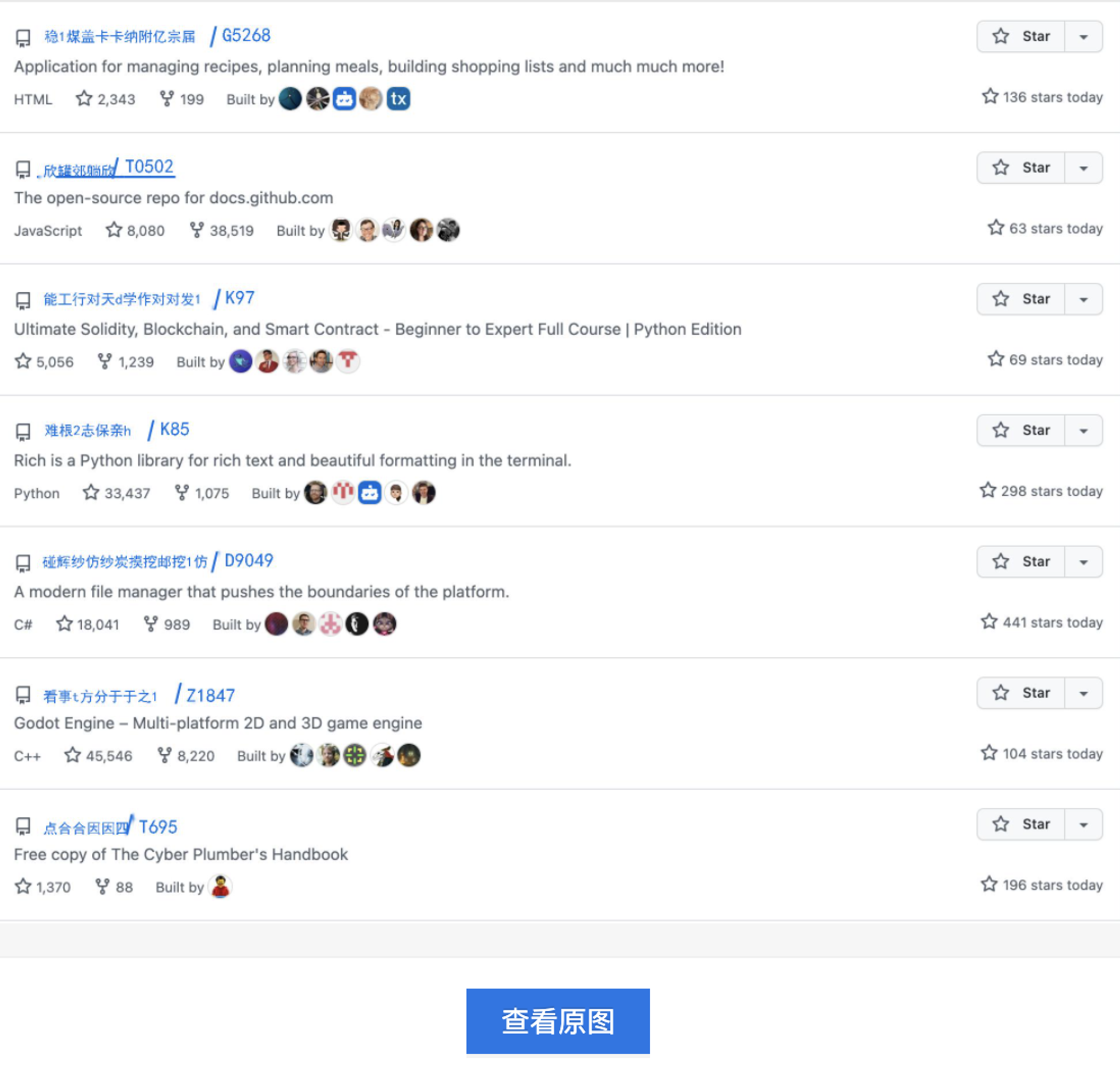
在数据生成页面已经自动对之前的标注框区域进行了处理,默认每个标注框使用随机的中英文填充。右侧面板中可以对每一个标注框设置不同的语料及样式。特意测试了张有纹理的图片,可以看到标注框区域的修改还是比较明显的。

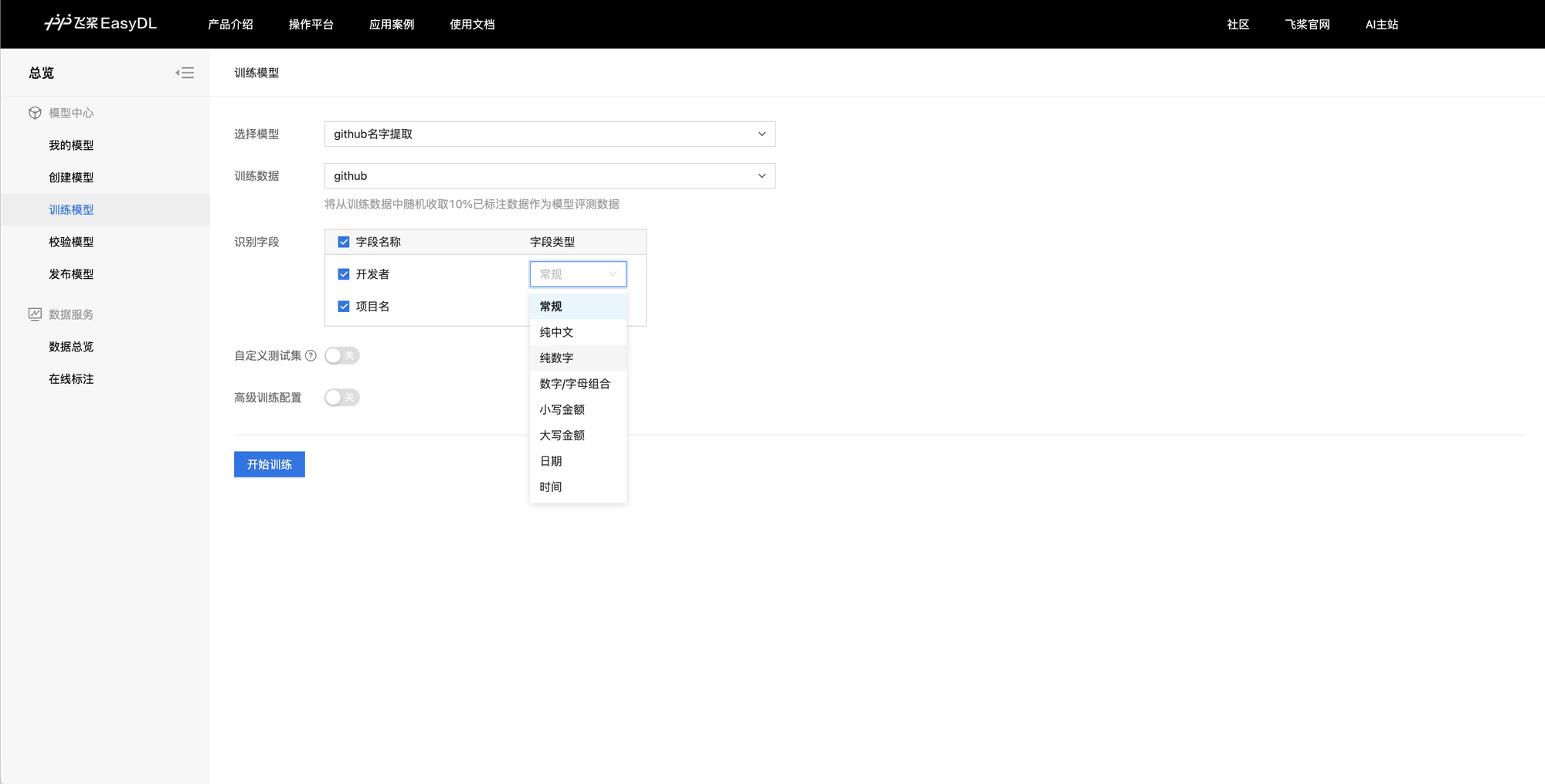
训练模型
启动训练时可以对目标字段定义一些常见的类型,例如纯中文,纯英文等,猜测是在后处理中会添加相应的矫正逻辑。高级训练配置中仅包含了训练轮数(40轮)以及图片 resize 的尺寸(512x512),除此之外没有其它任何参数。
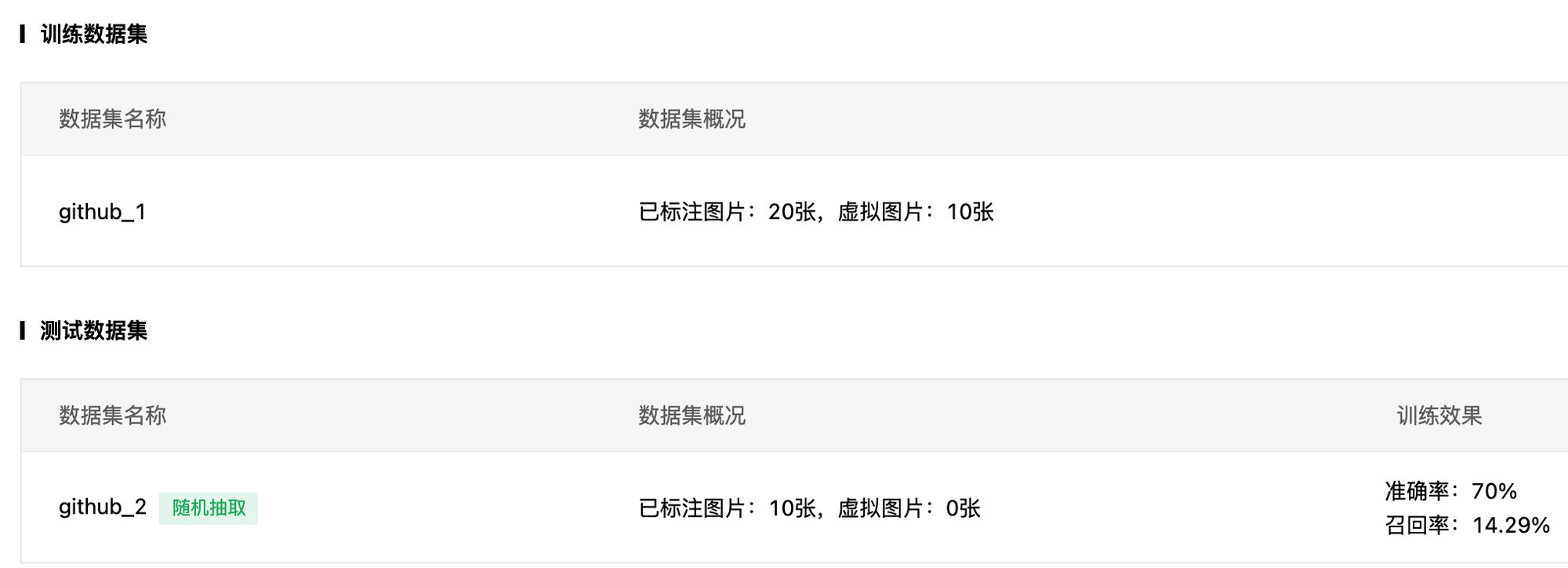
训练完成后,测试集上的准确率和召回率分别是 70% 和 14.29%,由于只有 30 张训练数据,所以这个结果也完全可以理解。
校验模型
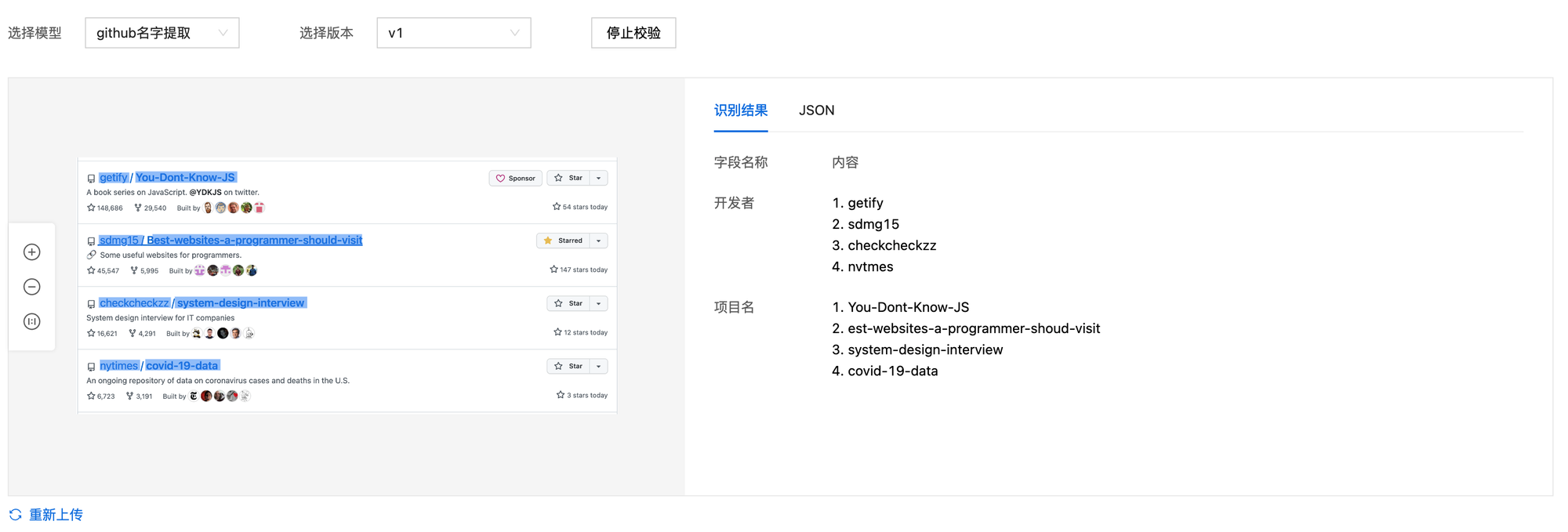
校验模型界面可以很方便地启动训练好的模型,并支持上传新的测试图片进行测试。因为测试集的指标较低,所以其实并没有报太大的期望,但结果却可以说是令人震惊的好,测试集中的图片在这里进行测试,几乎所有的所有者和项目名称都能提取出来,从 github trading 页面截取新的测试图片,也能够顺利预测出结果。
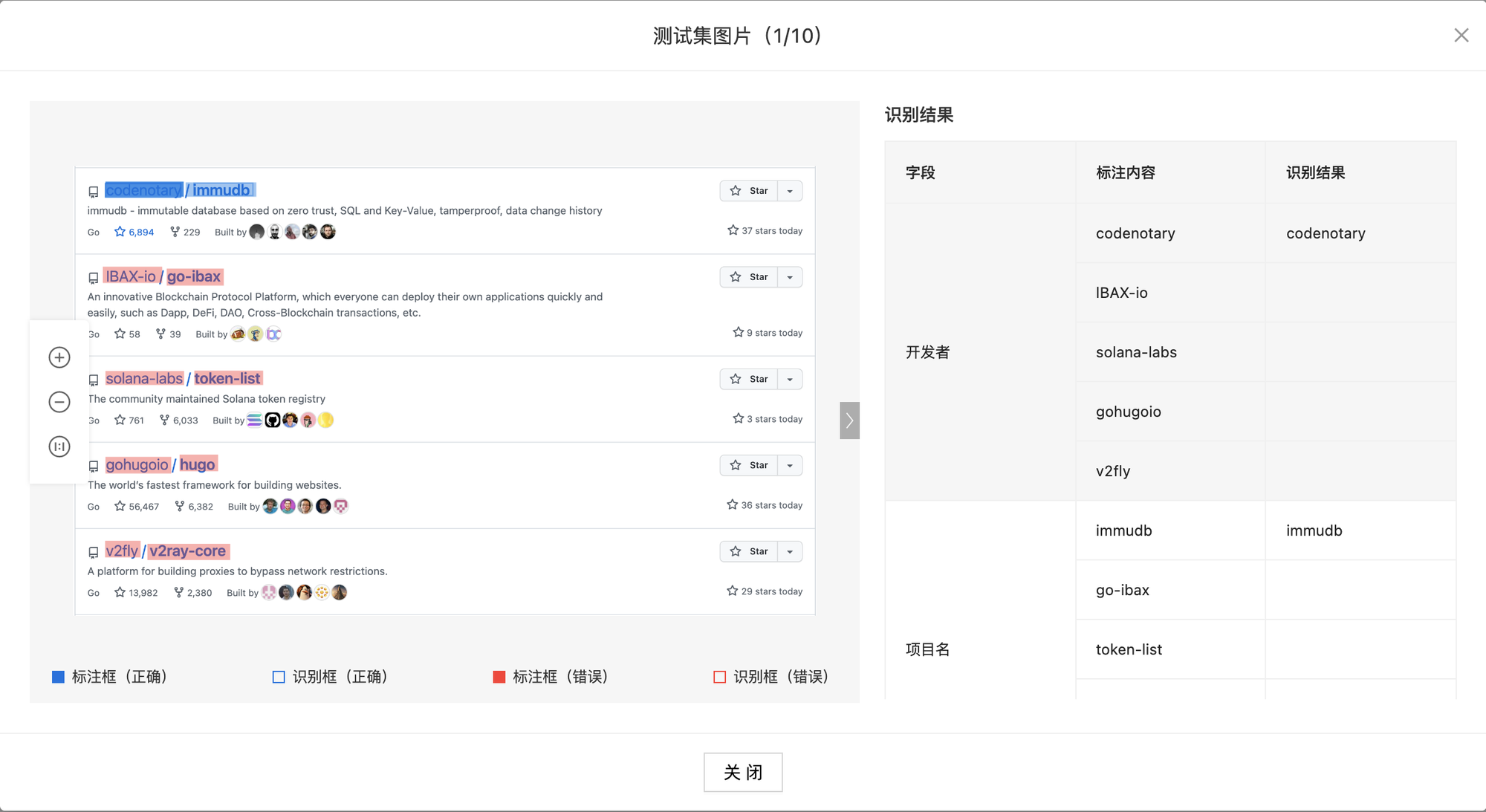
那为什么模型在测试集上的指标那么低呢?回过头看了下测试集的具体测试结果,发现所有图片都是只抽取了第一行的开发者和项目名称,难道是模型训练部分的评测代码有 bug?
总结
可以看到,整个流程当中完全没有提到文本检测、文本识别、结构化后处理等概念,用户能够以比较自然的方式来实现信息抽取的任务。最开始的标注内容(标注框位置+内容)在整个过程中起到了多种作用:
- 作为数据生成的目标框
- 作为测试集结构化结果的 Ground Truth
- 作为某个模型的 fine tuning 数据。官网的说明中有提到百度自研的「EnDet 实体检测」算法,但是很遗憾搜不到相关的论文。
总体感觉,EasyDL OCR 很好地限定了需求的范围,来简化产品的设计,提高用户操作的流畅性。OCR 场景中一些常见的定制化模块,如文本检测、文本识别、多票据 ROI 的检测、朝向检测、结构化后处理等等步骤都没有考虑进产品当中。
参考:



