Runway Green Screen 功能分析(一) - 交互式语义分割
date
Dec 20, 2021
slug
能够理解用户意图的分割模型
status
Published
tags
Computer Vision
Deep Learning
Segmentation
summary
能够理解用户意图的分割模型
type
Post
Runway 是一款在线视频创作工具,它的 Green Screen 功能可以方便地从视频里抠出各种物体进而用于视频创作,本系列文章尝试分析其 Green Screen 功能的实现原理。
本篇文章会分析绿幕功能的第一步,如何生成初始的分割结果。
交互式语义分割
图像领域有一个专门的研究方向为「交互式语义分割」,下面的 gif 是来自 RITM 项目,操作的流程和 Runway 的绿幕功能类似,从 gif 中可以直观地看到整个交互的流程和结果:用户通过鼠标点击,指定要提取的物体,算法给出一个初始的分割结果,对于初始分割效果不好的部位,可以通过补充点击使得分割效果变好,补充的点击分为两类,一是对网络没有分割好的区域补充点击( gif 中绿色的点击),使模型去补上漏的区域,二是对过检的区域补充点击( gif 中红色的点击),减少错误的预测。和一般的语义分割任务相比,最大的差异在于:模型能够理解「用户意图」。

读了两篇该领域的论文来了解大致的原理,一篇是 2016 年首次将深度学习应用于交互式目标选择的《Deep Interactive Object Selection》,另一篇是目前的 SOTA 论文《Reviving Iterative Training with Mask Guidance for Interactive Segmentation》。两篇论文的具体细节这里不会做介绍,主要总结下相比于一般的语义分割任务,加上了「交互式」这个前缀后实现起来会有什么差异。
如何对用户操作进行编码
上文中的 gif 采用的是用户点击的交互方式,其实还有些方法采用的是其它方法,如:
- 画一个包含目标物体的框
- 在目标物体上进行轨迹的涂抹
从直觉上来说,「鼠标点击」是最自然、操作最方便的形式。那么网络如何能对用户意图做出反馈呢?以鼠标点击事件为例,产生的最原始数据是图片中的一个二维坐标点,以及该点的类别是 Positive,还是 Negative,第一步需要将这些信息编码(encoding)成网络能够训练的形式,主要有以下几种方式:
- 以点击点位中心,画高斯圆
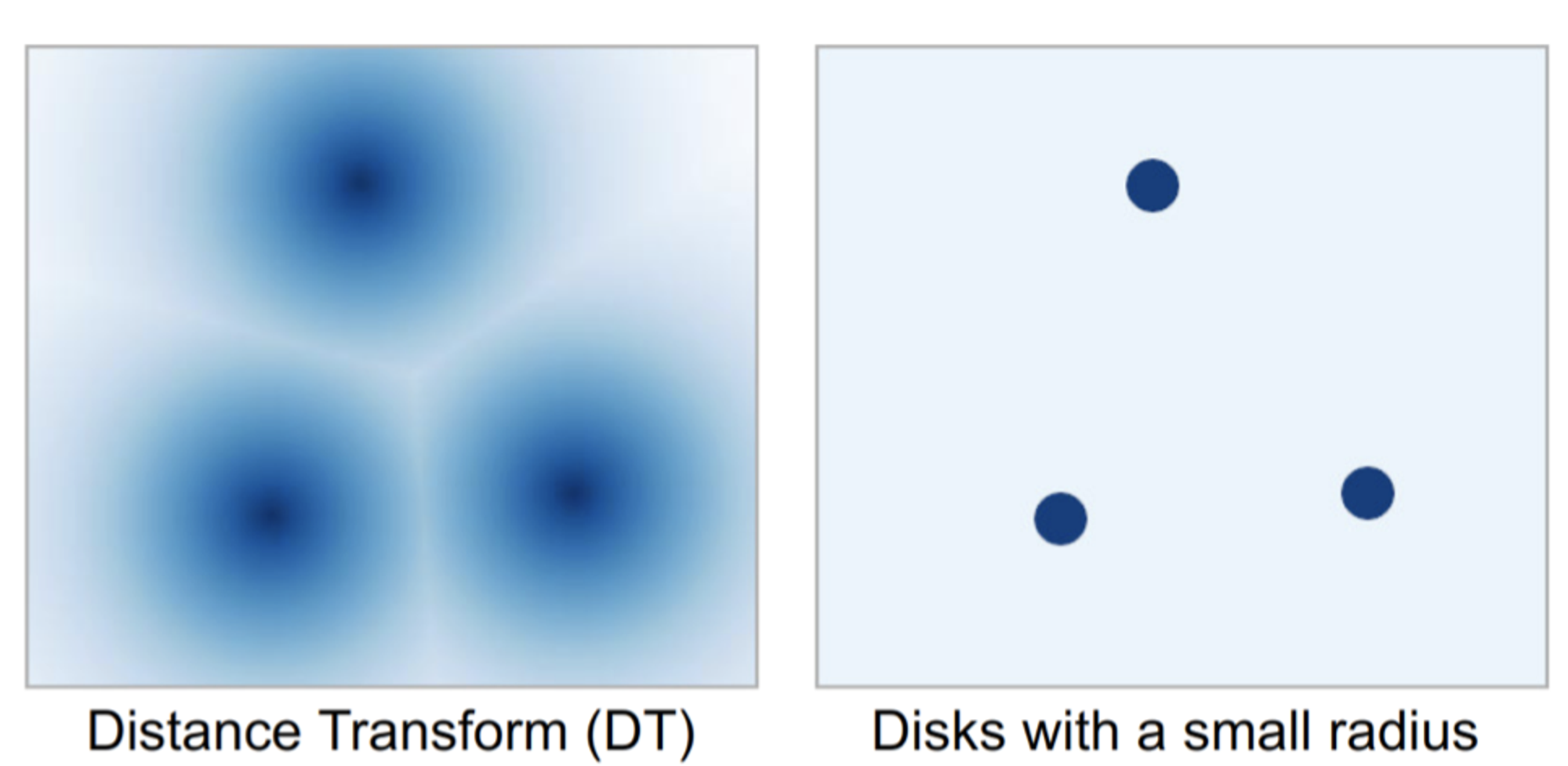
- 以点击点位中心,计算其它像素到该点的欧氏距离(Distance Transform)
- 以中心点为圆心画一个固定半径的小圆
用户行为编码结果如何送进网络
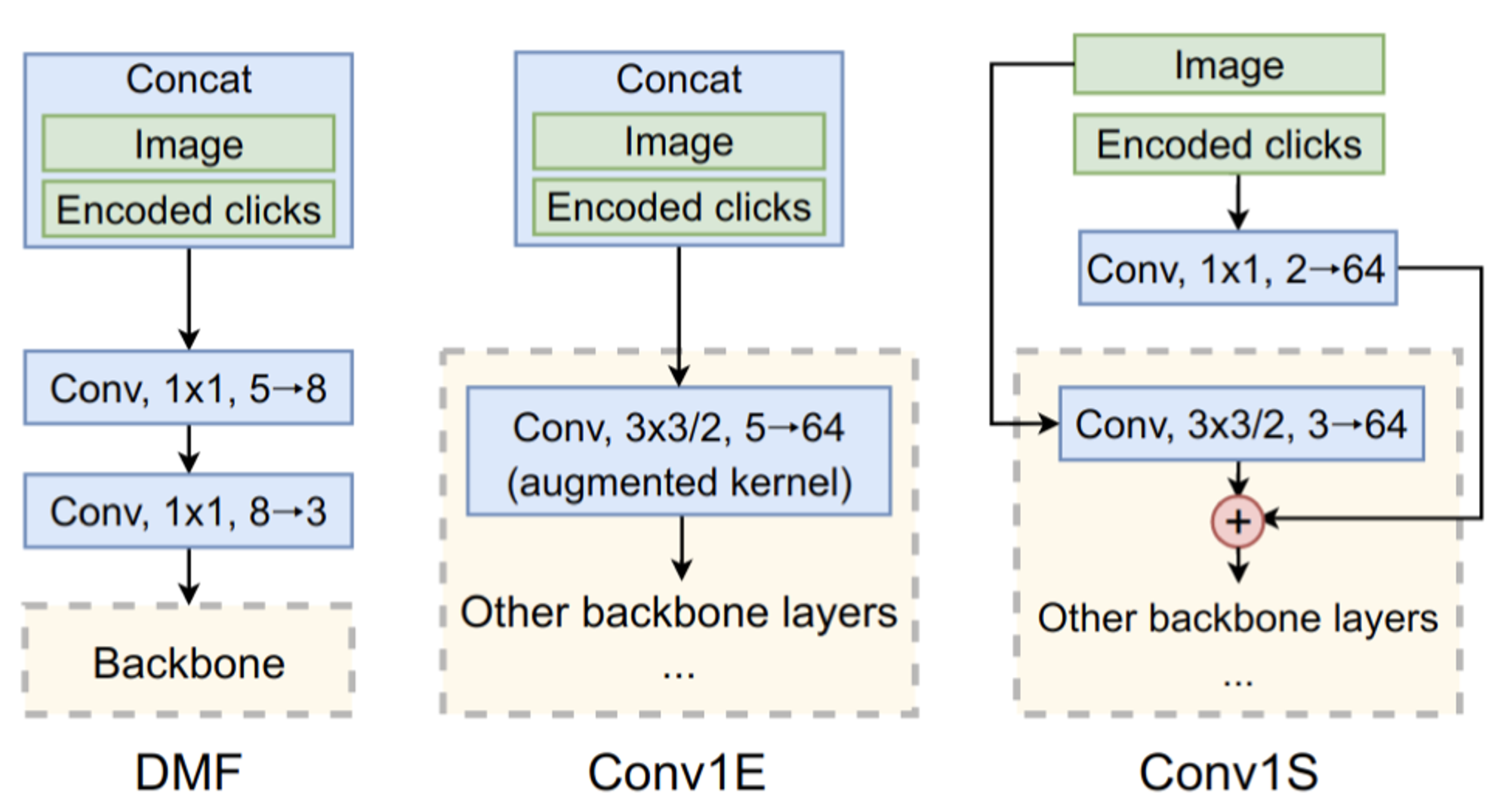
编码完成后相当于在原始图片的基础上多出来了两个通道,上图中是 RITM 中总结的几种融合方式。DMF 和 Conv1E 都是直接把图片通道和 Encoded clicks 通道 concat 在一起,这样输入的通道数就变成了 5,一般的预训练模型输入都是三通道,为了使得输入能够对齐,DMF 在 backbone 前单独加了两层卷积来做维度的转换,Conv1E 是直接把第一层卷积的输入通道数用 0 多初始化了两层,而 Conv1S(即 RITM 中提出的方法)是单独对 Encoded clicks 加一层卷积,卷出和 backbone 第一层 Conv 输出通道相同的维度,再相加。论文中的结果是 Conv1S 稍好,不过在官方项目里,作者也提到了 Conv1E 和 Conv1S 结果其实差不多。
损失函数
和一般的语义分割相比,交互式语义分割在损失函数方面有两点差异:
- 交互式语义分割是一个二分类问题,即只有用户想要的前景,和用户不想要的背景两个类别,所以损失函数用的是 BCE。当然其它 BCE 的变体如 Focal Loss 等适用于二分类问题的损失函数都可以尝试。
- 计算 loss 时,只以用户选中的目标物体的 mask 作为正样本,即使图片中有语义上相同类别的其它目标,都会被当成负样本。
如何模拟用户点击
既然网络需要学习用户的点击行为,那我们的标注数据就需要有用户的点击事件,通常是采用模拟的方式在训练时生成,最简单的就是根据 GT Mask 来随机的选取。但很明显,随机的选取不符合用户实际的行为,没有用户「一般会点击主体中心附近」这一先验知识体现出来。TODO:补充 sample 的策略
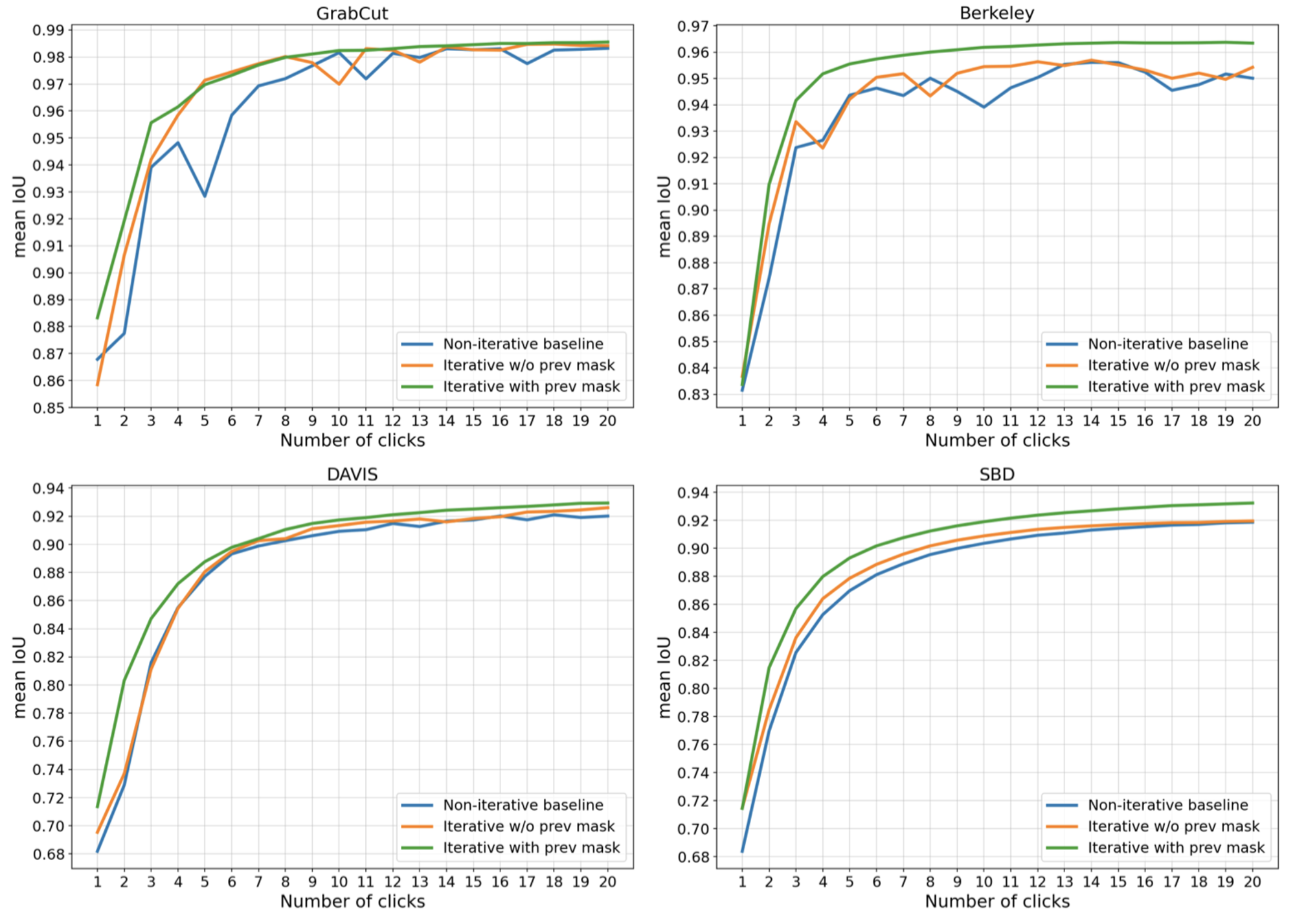
训练策略-迭代式训练
「迭代式训练」也是 RITM 的主要贡献之一,出发点也是模拟用户实际的操作行为:在主体 mask 分割出来以后对不满意的区域进行修补。为了让模型能够感知到上一步的用户操作,RITM 中会把上一步的分割图同样作为一个通道 concat 在网络输入中(第一次 concat 一个全 0 的通道)这样就能让网络「看到」上一次的结果,实验也证明了迭代式的训练方式对效果有提升。
如何评价模型的性能
常用的评价指标有 Noc@90,含义是:目标物体的标注与分割网络的输出之间 IOU 超过 90% 所需要的用户点击的次数,该指标越小越好。一个问题是,不同的点击行为模型输出的结果是不一样的,所以需要定义好固定的点击行为,即每次是点击目标物体的中心点(应该还有些其它约束,待考证)。
后处理
《Deep Interactive Object Selection》中采用的是 FCN 结果,网络输出的结果还要使用 Grabcut 这类传统算法才能获得边界效果比较好的分割结果。
而在《Reviving Iterative Training with Mask Guidance for Interactive Segmentation》中,由于使用了较新的 backbone(HRNet);采用了更大的数据集(COCO+LVIS);更现代的训练技巧等原因,即使不使用后处理也能获得很好的分割结果。
传统算法补充

传统方法中比较经典的方法有 Grabcut,用户框出目标物体即可进行初步分割,如果想进一步优化分割结果,可以对某些确信区域、难点区域(如上左图中的白色、黑色线条)进行涂抹以修正 Mask 结果,OpenCV 有
cv2.grabCut 接口可供调用,官方也有一个 demo 示例。