Mindee 文档解析平台
date
Feb 28, 2022
slug
Mindee 文档解析平台
status
Published
tags
OCR
Platform
summary
好像不太实用
type
Post
这次体验的平台是 Mindee,这是一家提供在线文档解析的公司,除了现成的 API,也开放了自定义文档的模型训练、部署等功能,去年融资了 1400 万美元。 官网首页的动画还是做的挺好看的,起到了很好的示意功能,帮助客户理解公司的价值。

首页上可以直接体验现有 API 的效果,种类不多,主要是针对欧美的文档。示例文档返回的结果里可以看到有
Orientation 这个 key,说明做了旋转的处理。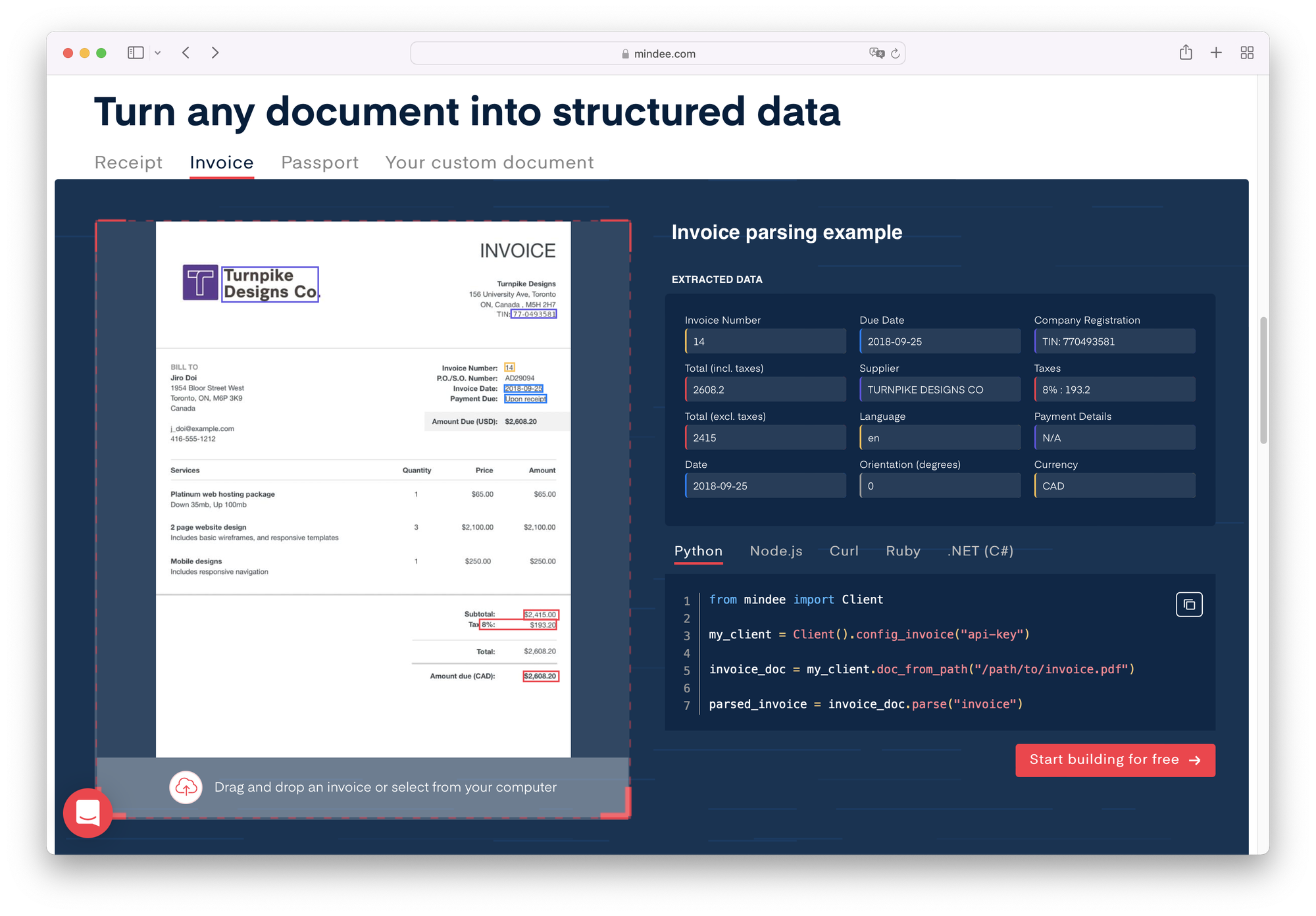
Mindee 有一个开源的 github 库 doctr 能够实现文本检测和识别模型的训练、推理,和 paddleocr 类似。
这次体验使用的数据和百度 EasyDL OCR 平台体验使用的数据一样,也是 github tranding 的截图。
模型创建
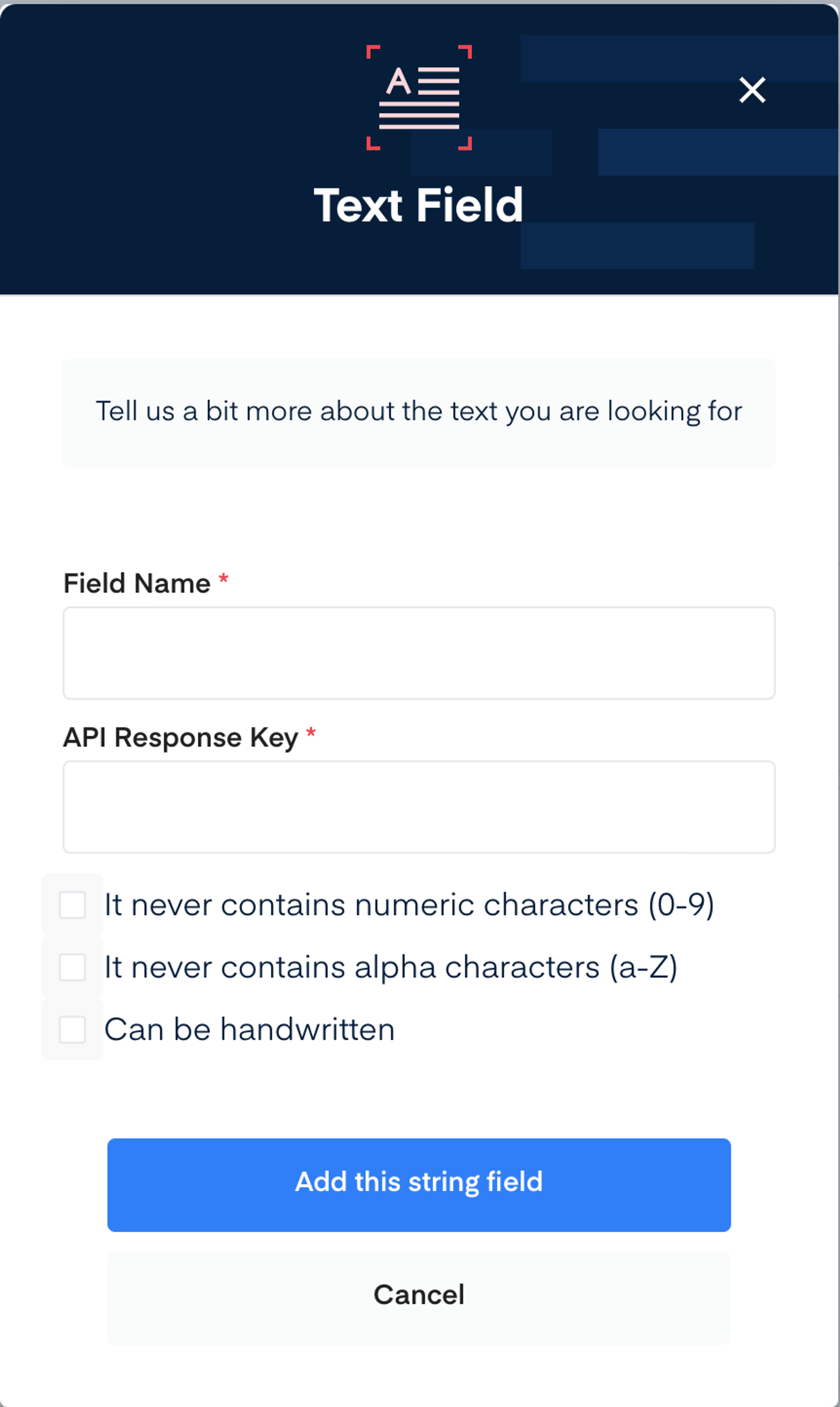
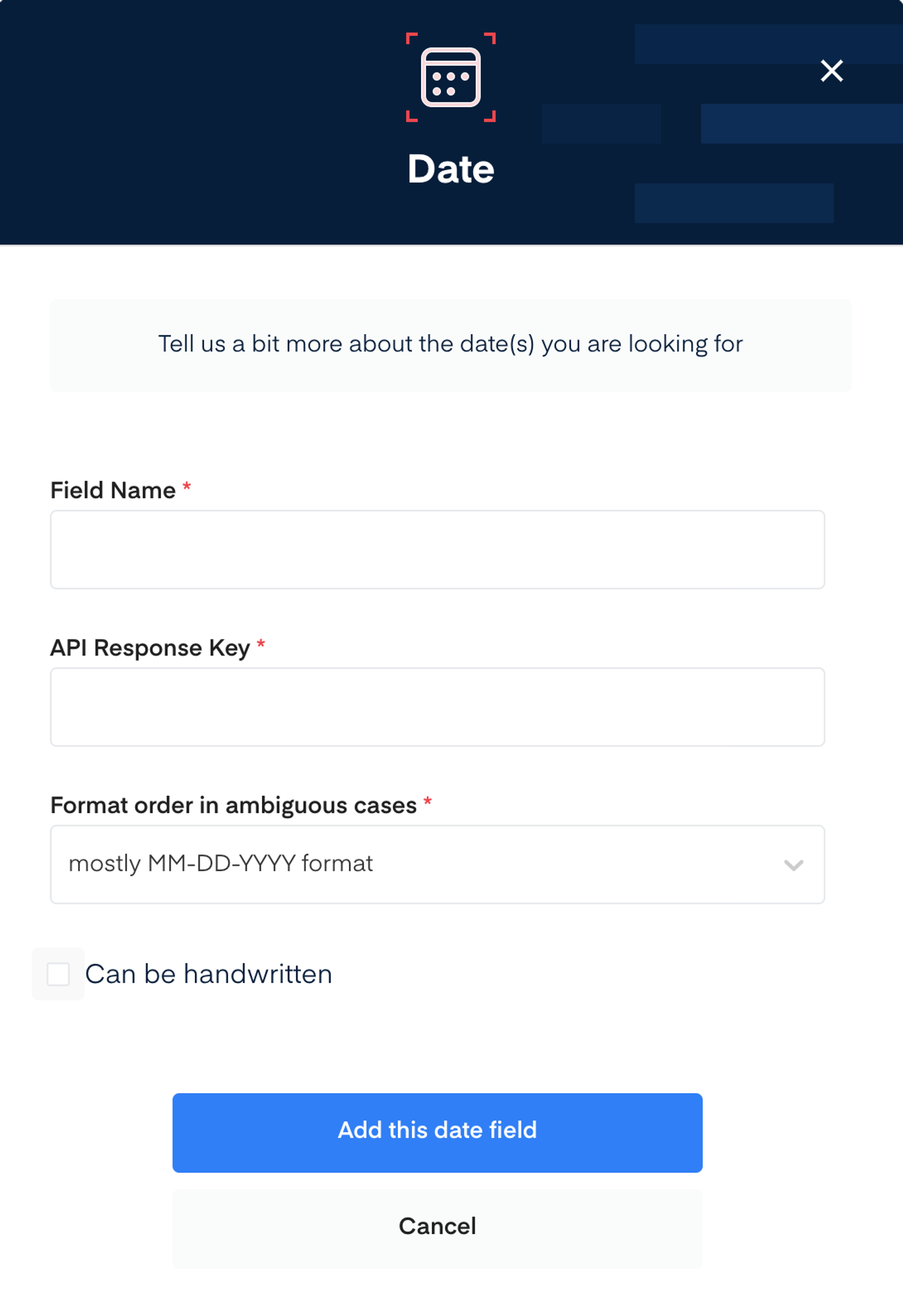
在模型创建页面需要定义模型要提取的字段,预制了几个常用的字段类型,例如 Number,Date 等。

不同的字段有个字对应的选项,例如 Date 字段可以定义归一化的输出格式。
数据标注
定义好模型字段后进入标注界面,右上角会有标注进度、模型训练计划提示。在标注到一定数量的数据时会自动进行模型训练,训练完成后会自动部署。标注数据的数量分为几个阶梯:
- 0 ~ 100:每 20 张数据训练一次模型
- 100 ~ 300:每 50 张数据训练一次模型
- 300 ~ 600:每 100 张数据训练一次模型
- 600 ~ 1000:每 200 张数据训练一次模型
标注界面的操作很简单,或者说很简陋也不为过。word 级别的文本检测结果会显示在图片上(无法查看识别的结果),通过点击文本框为其打上 Tag(前面我们定义的字段)。不支持框选操作,只有单击操作。
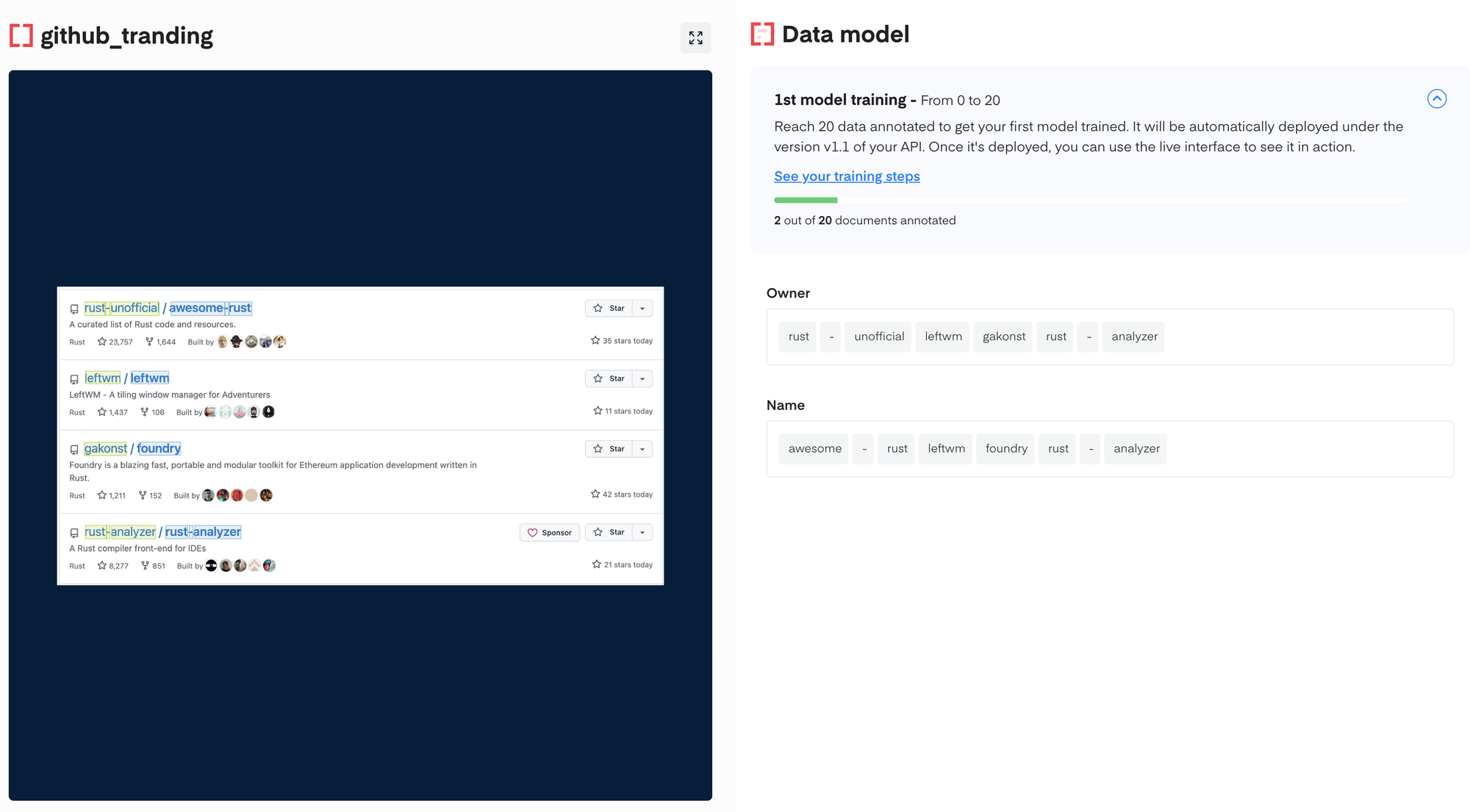
因为是 word 级别的检测框,如果要标注的内容很长,那标注体验其实是很糟糕的,例如下图。

还有个问题是检测框可能会不准,无法进行修改,也无法查看检测框内的文本识别结果是什么。对于没有 OCR 背景的客户来说,感觉这可能造成困惑:遇到这种情况我该怎么办?相比之下,百度的 EasyDL OCR 的标注操作就显得自然很多。
模型训练
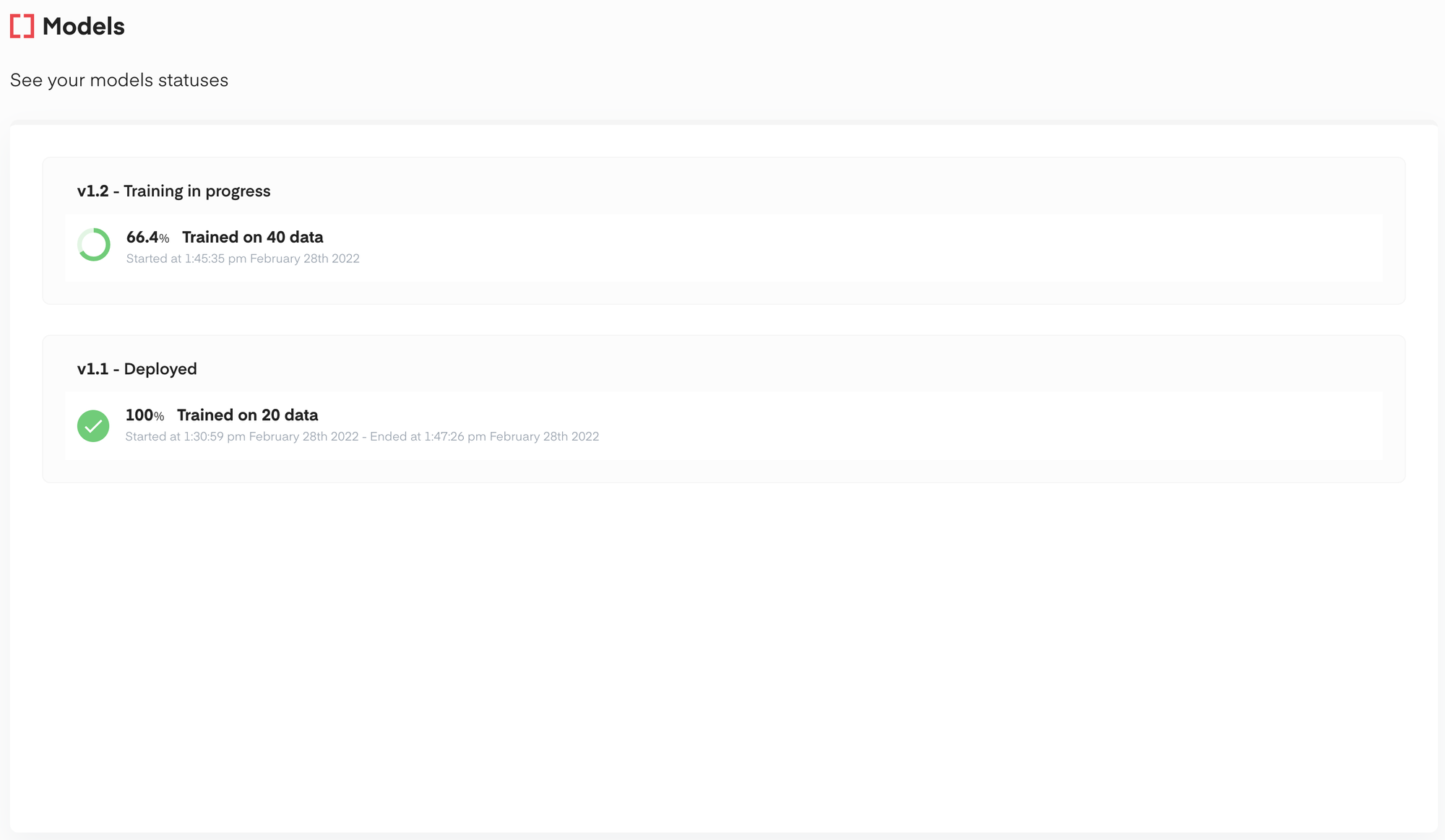
达到一定数量的标注数据后,模型会在后台自动训练,使用者不需要关心硬件资源、训练超参,完全自动无感,训练界面如下。
模型测试
整个训练流程没有测试集的概念,训练完成后无法评估模型的效果,训练好的模型会自动部署,能在
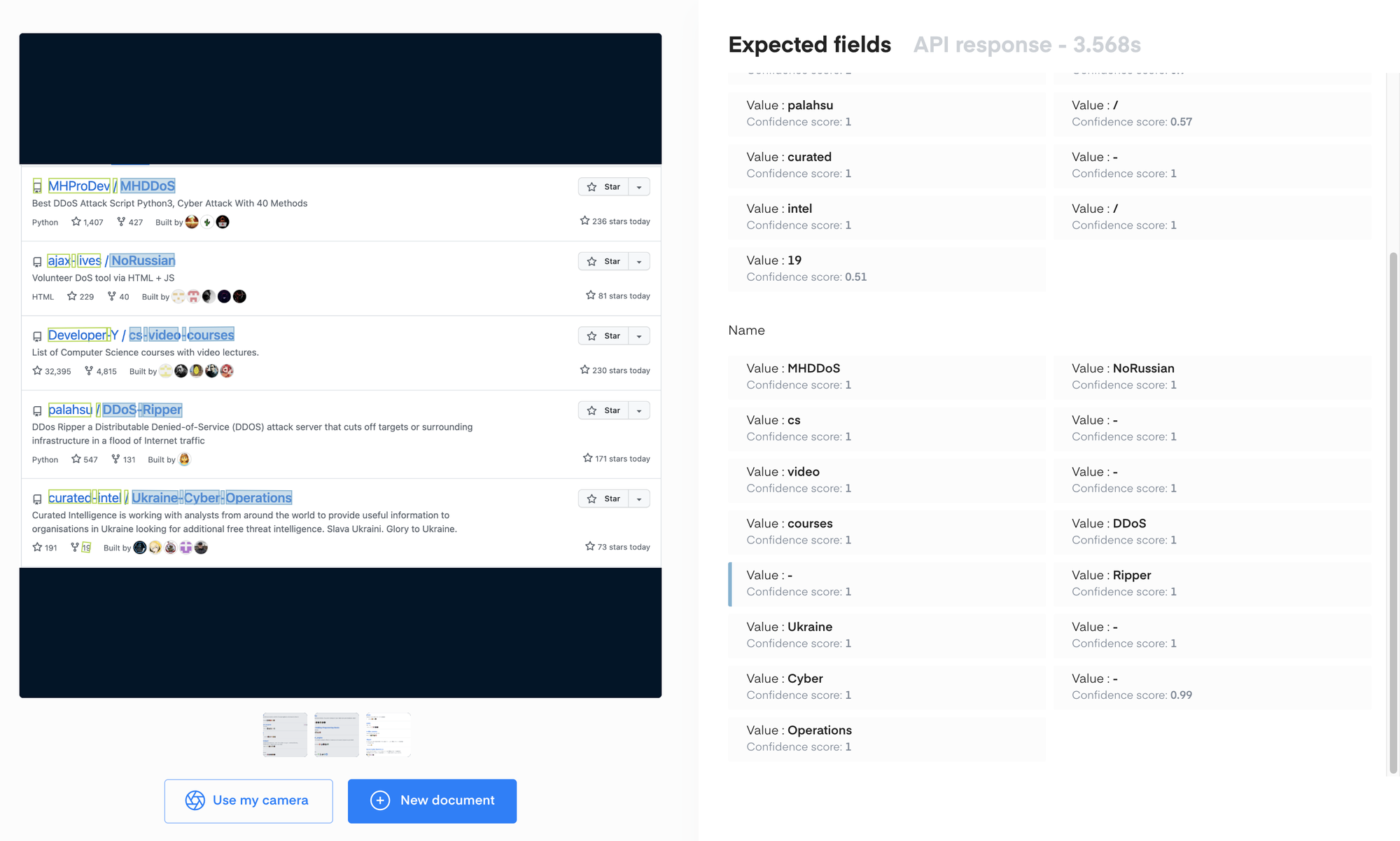
Live Interface 界面手动上传图片进行测试。从测试结果可以看到,API 返回的结果与其说是结构化结果,更像是文本框分类结果,虽然准确率还行,但有一个很大的问题:客户没法儿直接用,同一个实体被分成了多个文本框,还需要不少的后处理合并才能产出真正的结构化结果。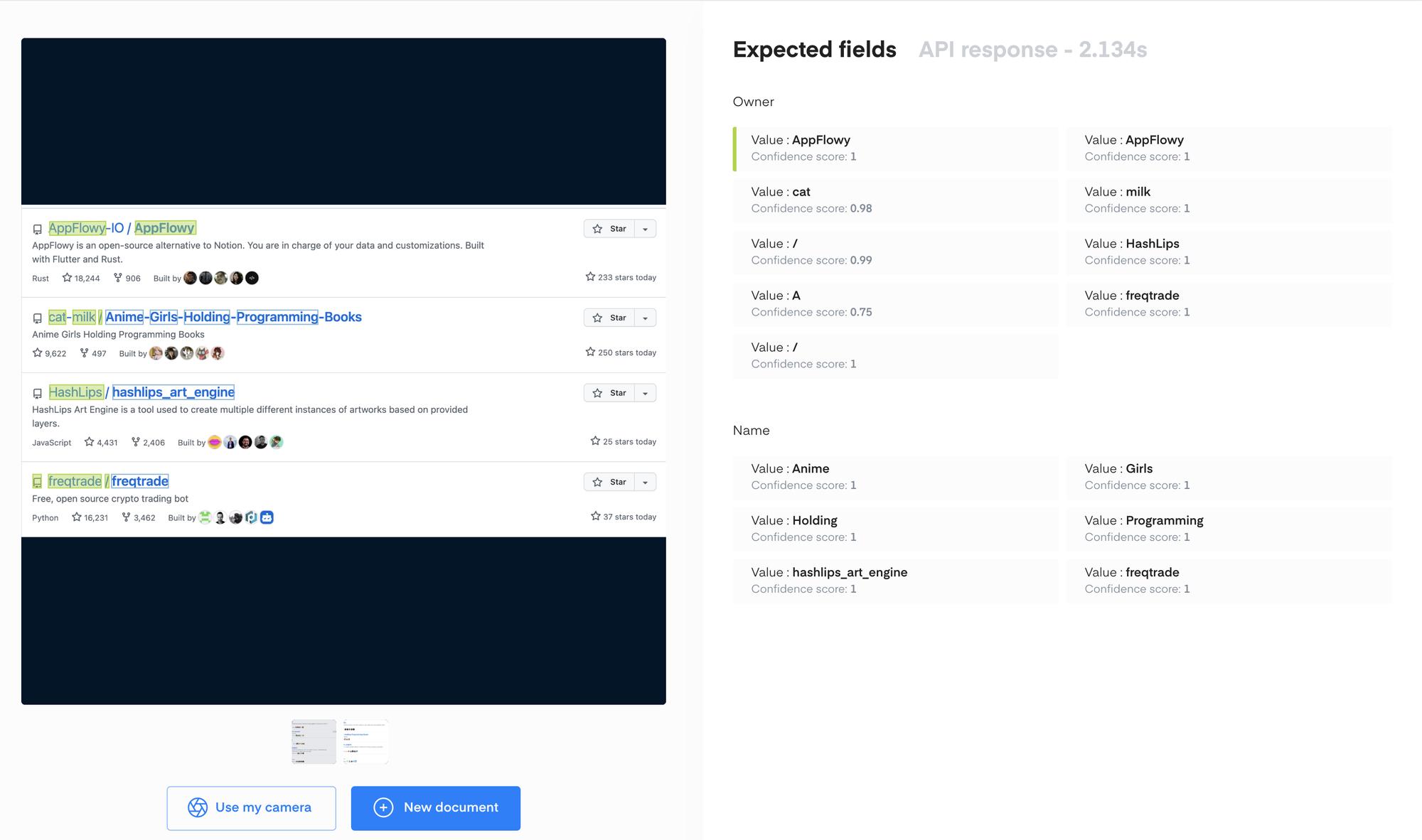
总结
为什么采用 word 级别的文本检测?
信息抽取的任务通常需要从连续的文本中提取有效的信息,这也是写规则的难点之一。百度 EasyDL ORC 通过直接框选目标信息的方式来做,底层应该也依赖于 word 甚至 char 级别的检测。Mindee 则选择直接把 word 检测的结果暴露给客户。
关于训练流程的简化
整个训练流程没有测试集的概念,Mindee 的产品经理或者工程师不可能不知道这个概念,只能说是有意为之,对于 OCR 从业者(或者了解基础深度学习模型训练流程的用户)来说,有点不可理解,没有测试集怎么敢上线新的模型呢?但是对于普通用户,这确实简化了产品概念。