Nanonets 平台试用
date
Mar 7, 2022
slug
Nanonets 平台试用
status
Published
tags
OCR
Platform
summary
功能比较全面,标注流程还有待优化
type
Post
这次体验的平台 Nanonets,创立于 2017 年,2 月份刚进行了 A 轮 1000 万美元的融资。定位和 Mindee 很像,也是做文档自动化平台,体验下来感觉比 Mindee 强大很多,相比起来 Mindee 有点像“玩具了”。
创建模型
平台本身内置了几种模型,相比于国内大厂的接口,种类算是很少了,可能和公司的策略有关,不想投入太多精力在预制模型的开发上,希望用户自己使用平台来出模型。
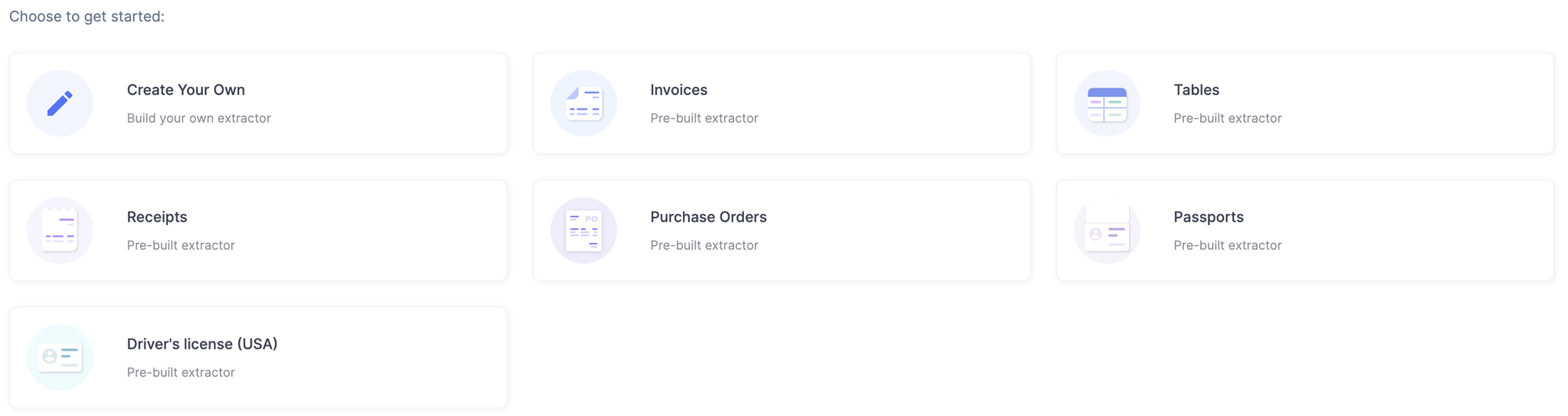
点击「Create Your Own」后可以进入自定义 Label 界面,定义模型要提取的字段。
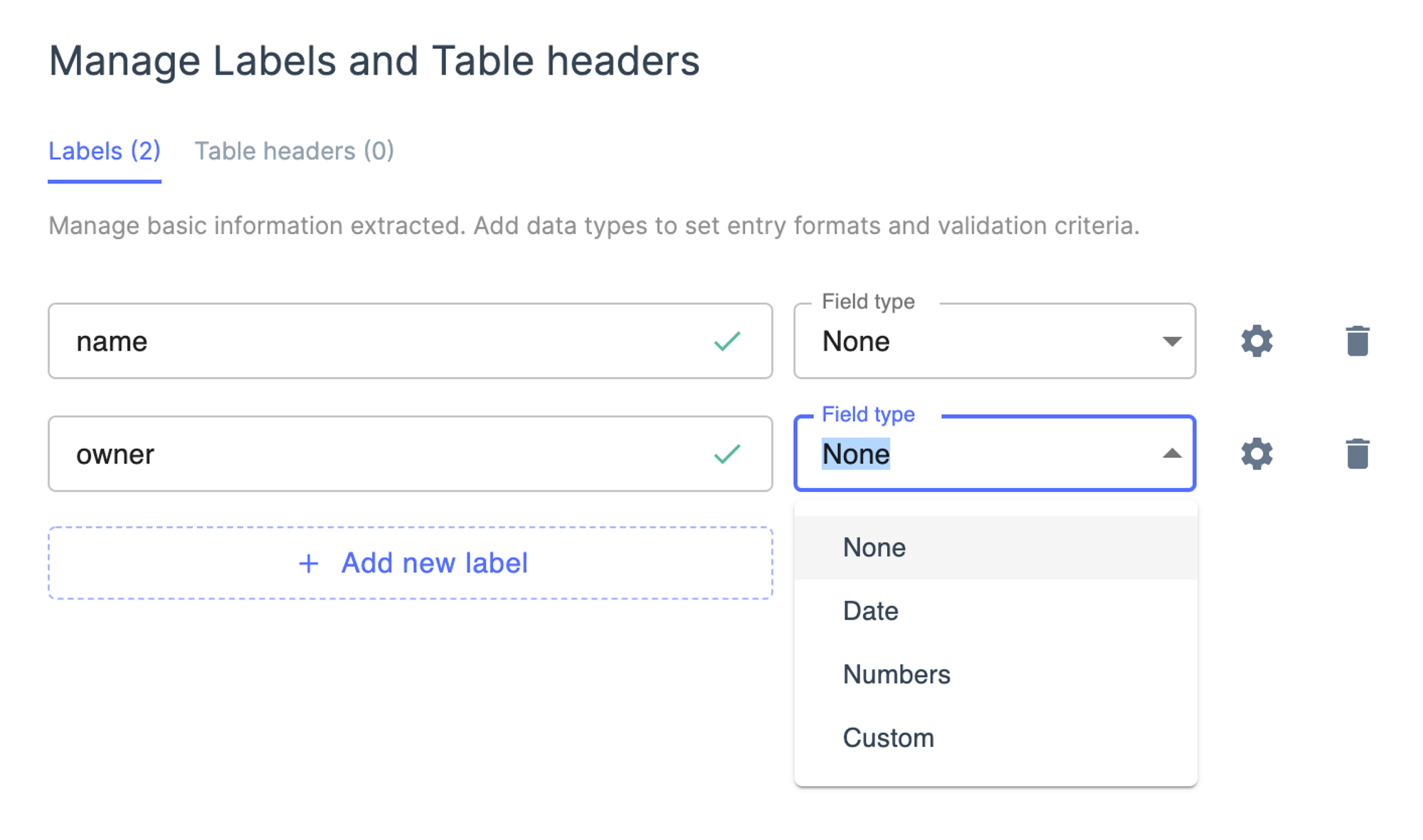
「Field Type」中可选的类型很少,不过点击右侧的设置按钮后,可以为每个字段设置专用的后处理,其中最灵活的就是可以使用自定义的 python 脚本来进行后处理。
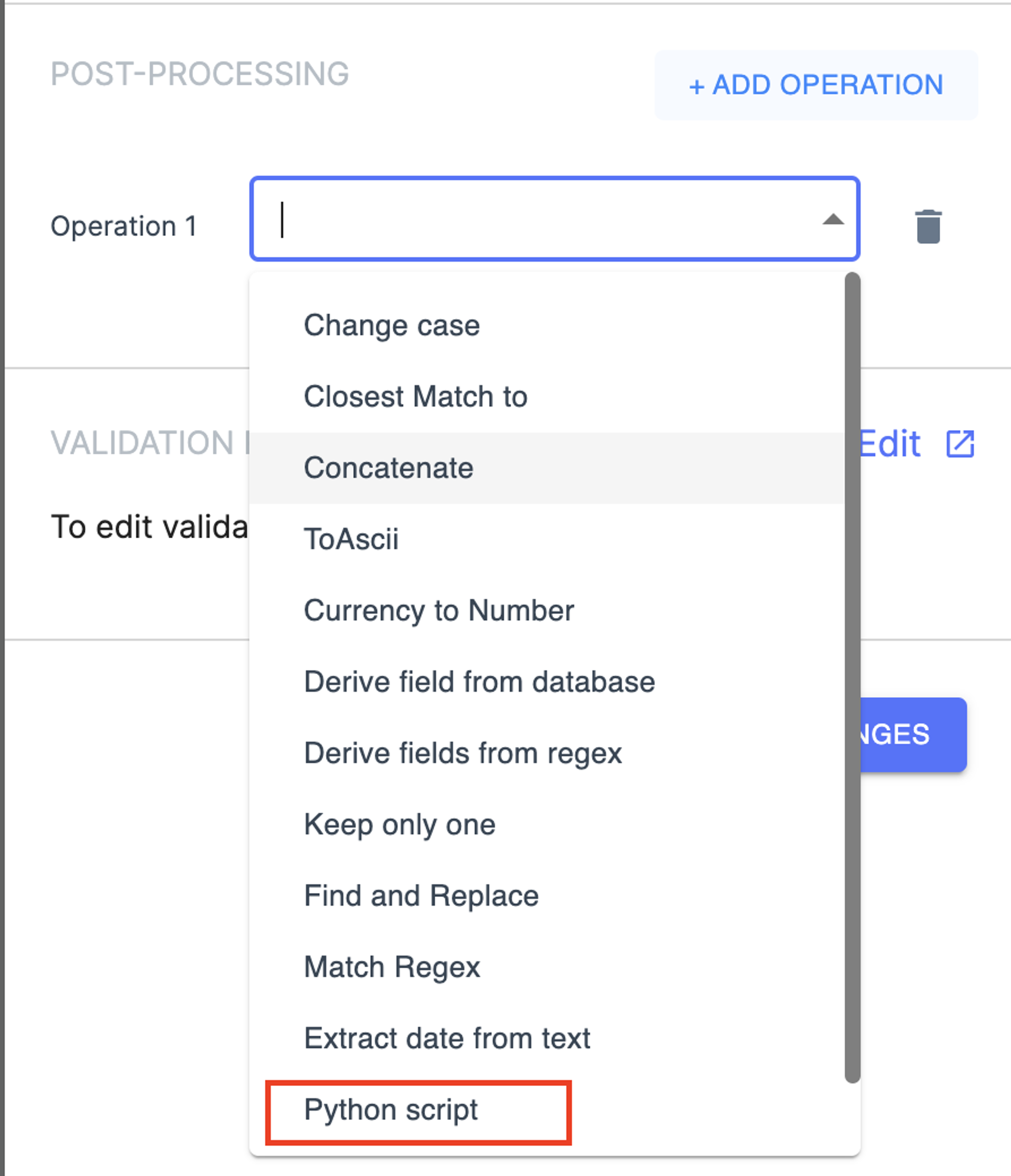
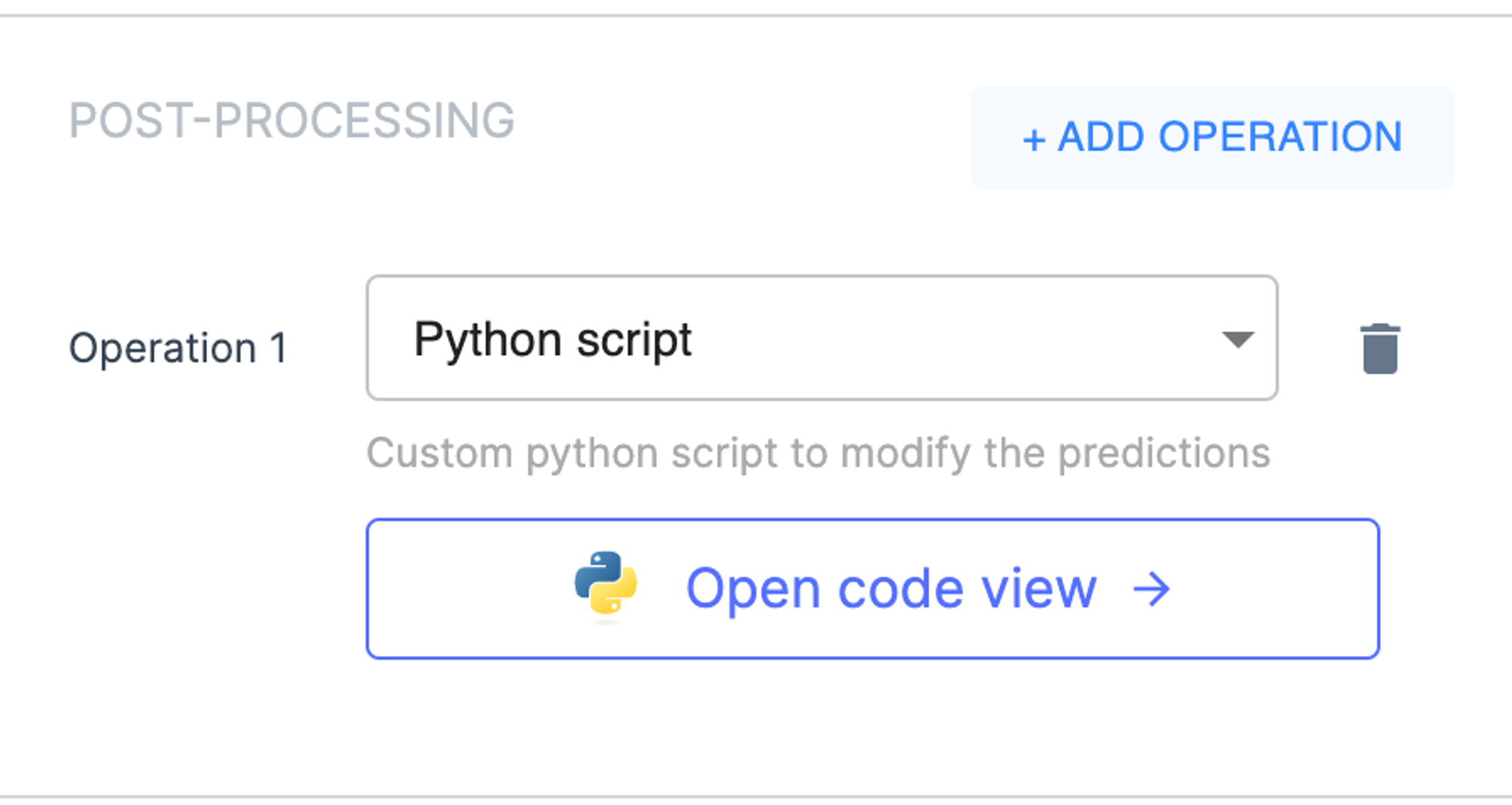
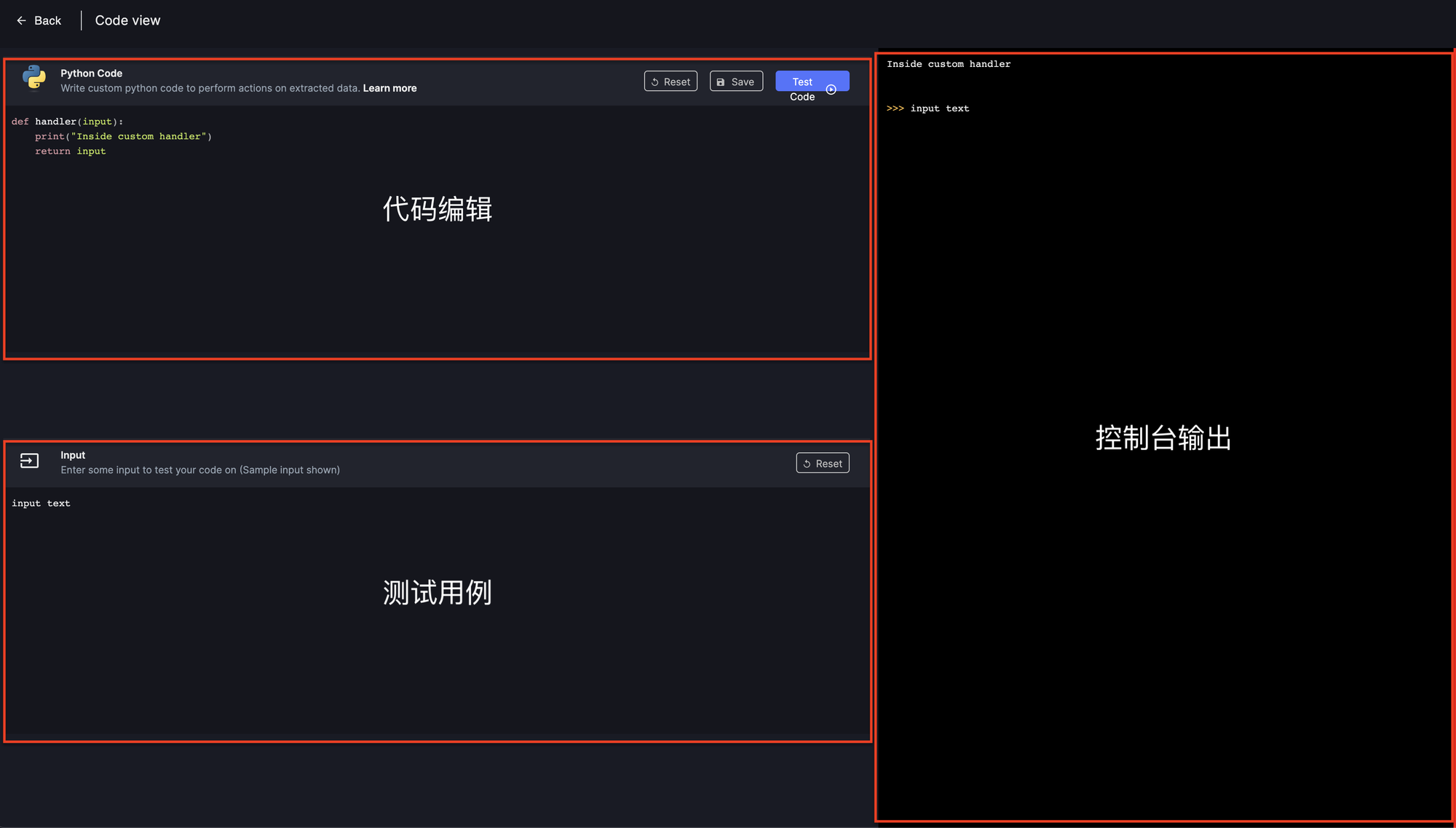
点击 「Open code view」后会进入到简易的在线 IDE,可以进行 python 代码的编写和调试。这个功能是百度 EasyDL OCR 和 Mindee 都没有的,做过 OCR/NLP 的应该都经历过往后处理里面加各种 ad hoc 代码,这个功能很实用。
数据标注
标注界面如下图,方式和百度 EasyDL OCR 类似,也是框选要提取的内容。但实际体验却糟糕很多,整个标注流程比较痛苦。下面来一一吐槽。
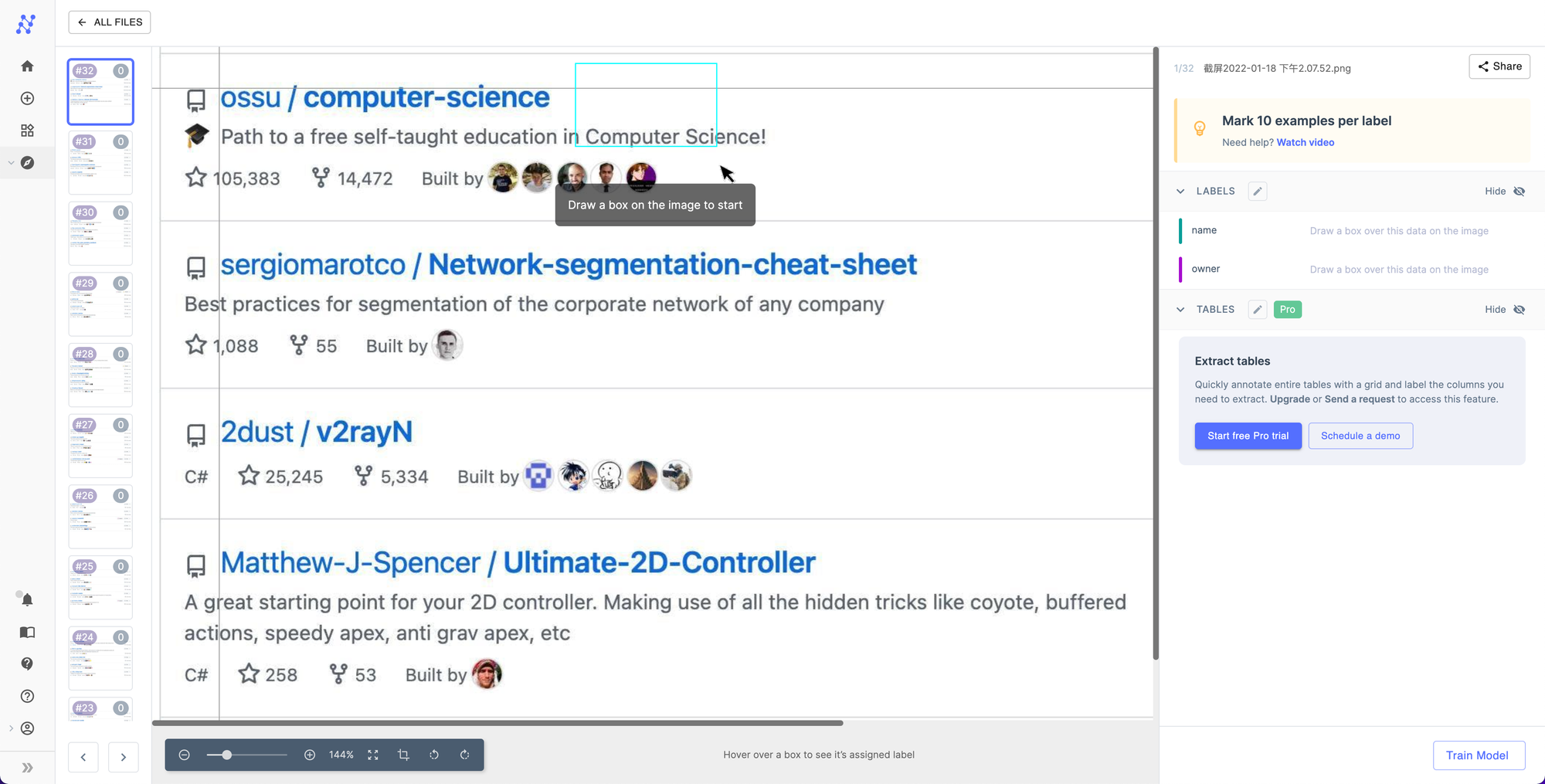
每次框选都需要选择字段类别,而且没有快捷键可以用,效率很低。对比百度 EasyDL OCR,是先固定一个标签后再去框选。
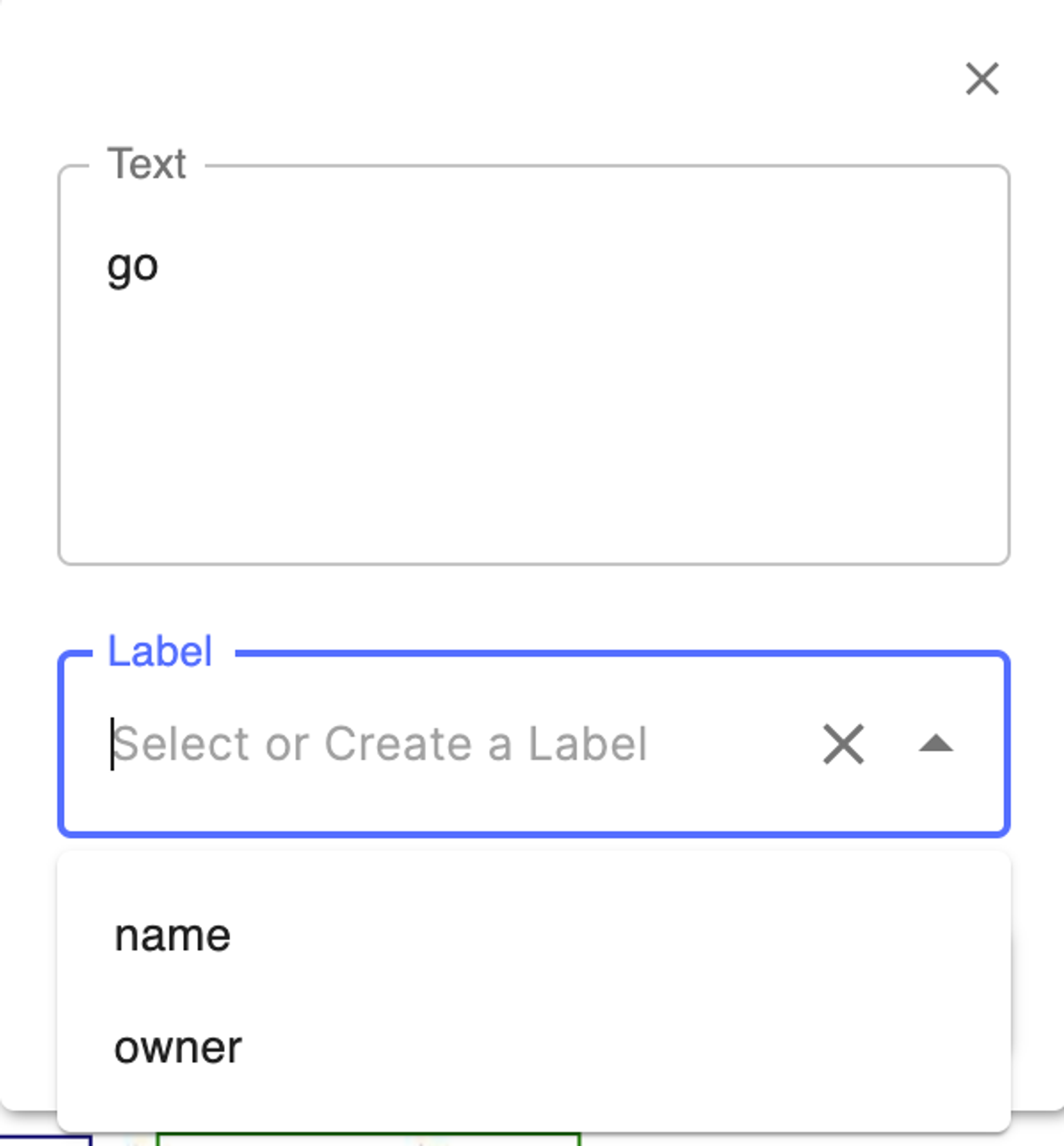
框选后识别的结果也比较糟心,几乎所有 owner 前面都会有识别错的大写字母 A。有时候甚至会出现只识别了一个字母的结果。
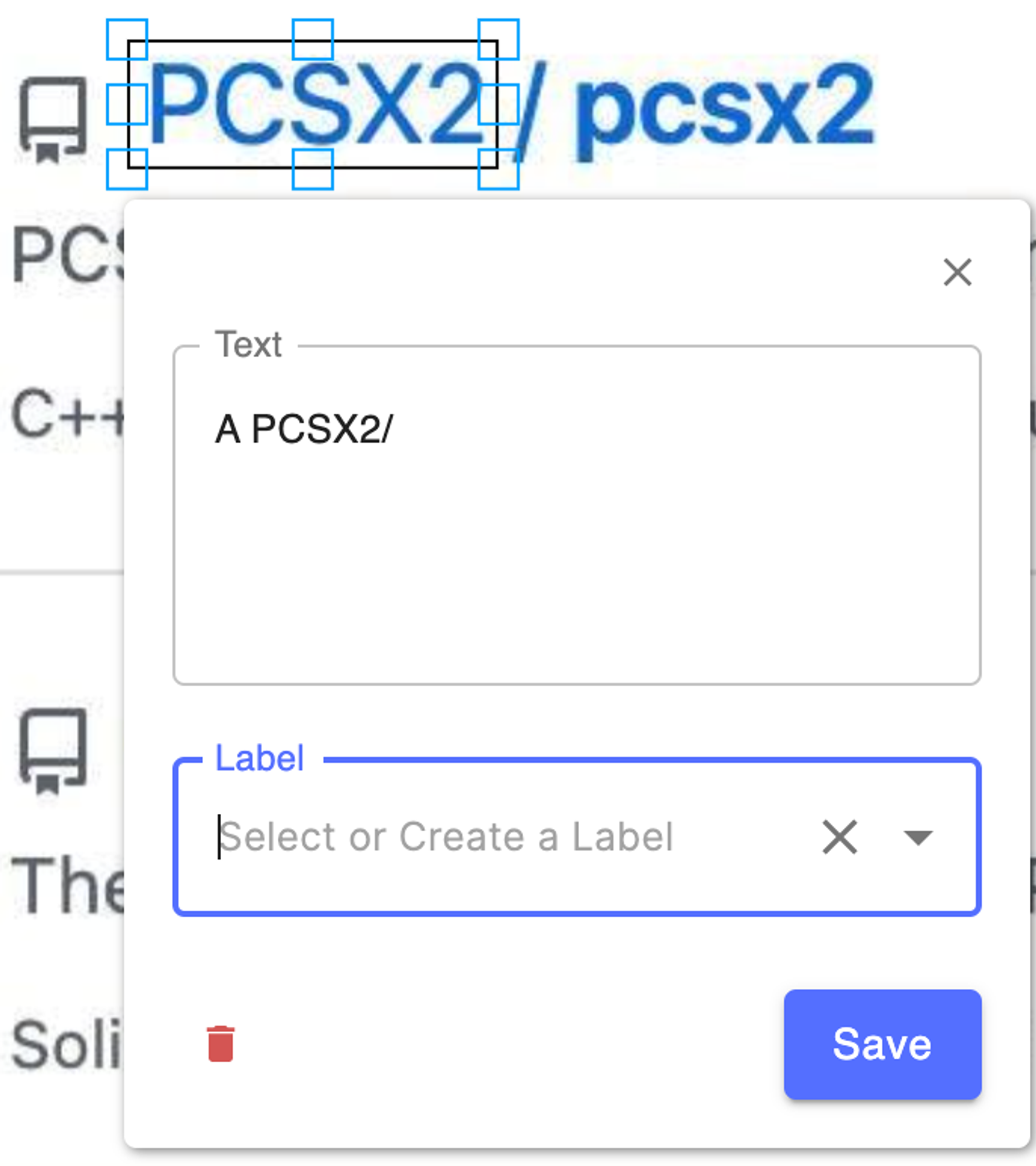
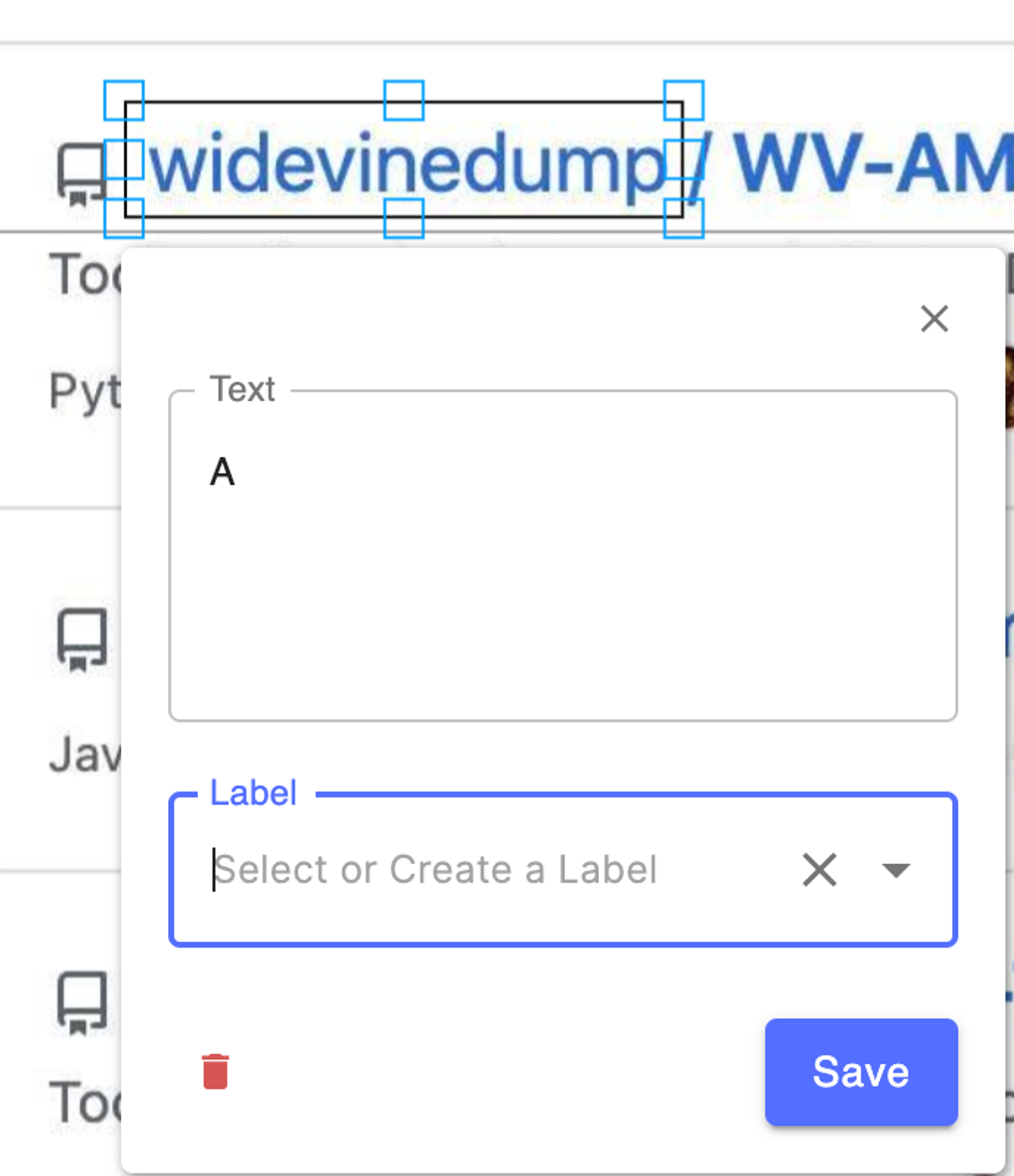
明明框的是 Ultimate-2D-Controller,但是识别结果却包含了 owner 部分的内容。很可能是因为文本行检测没有分开 owner 和 name。
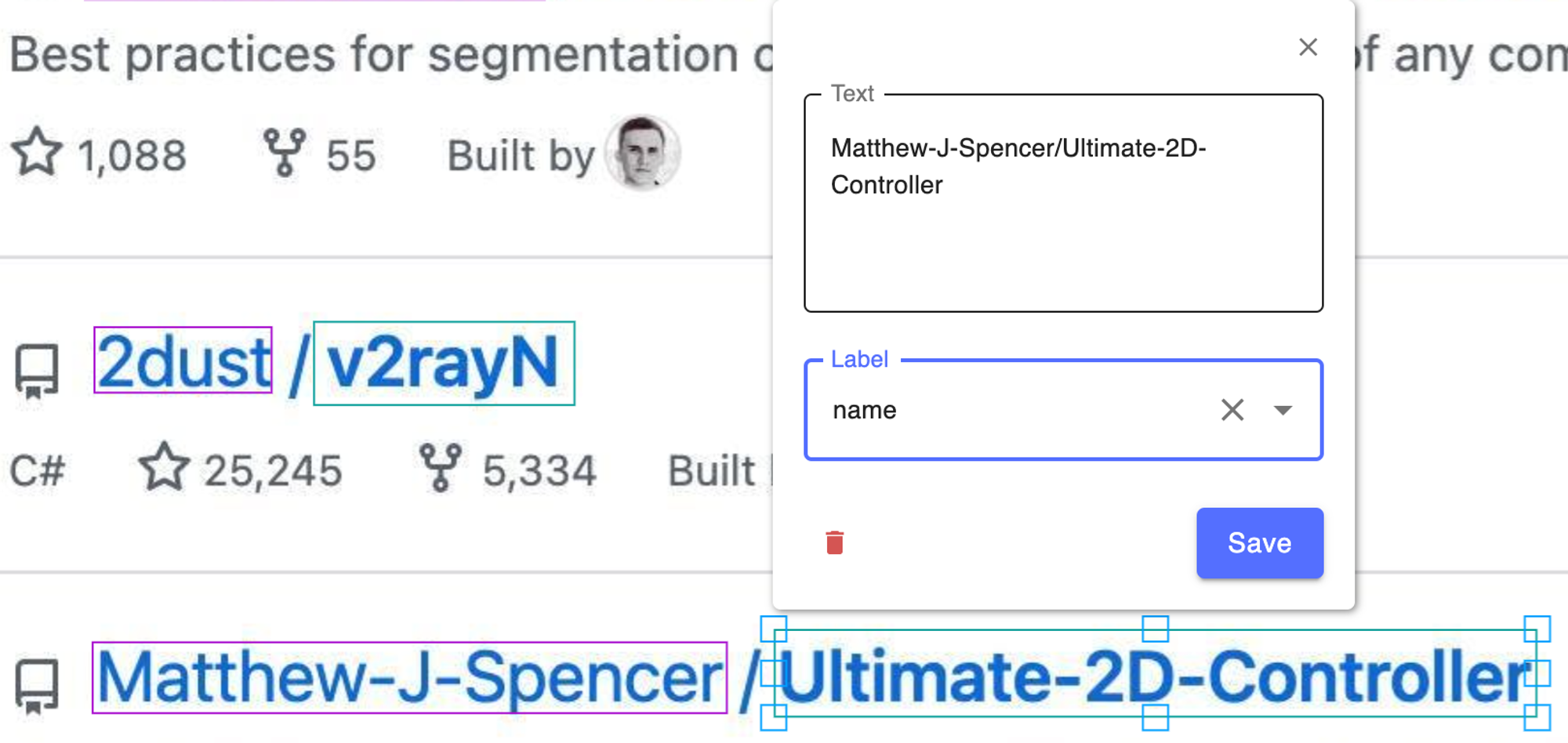
页面上没有保存按钮,切换图片自动保存,但是没有任何提示,一开始有点困惑,会担心数据没有保存,不过习惯了以后也还好。
模型训练
标注数据满足最低数量要求后(10张,并且每个字段也有一定数量要求)就可以开始训练了,之后再继续标注新的数据可以随时增量训练。
模型训练界面也很简单,没有任何参数需要调整,隐藏了所有细节。几乎没有等待硬件资源的时间,训练过程也很快,训练完成后模型也自动部署好了。
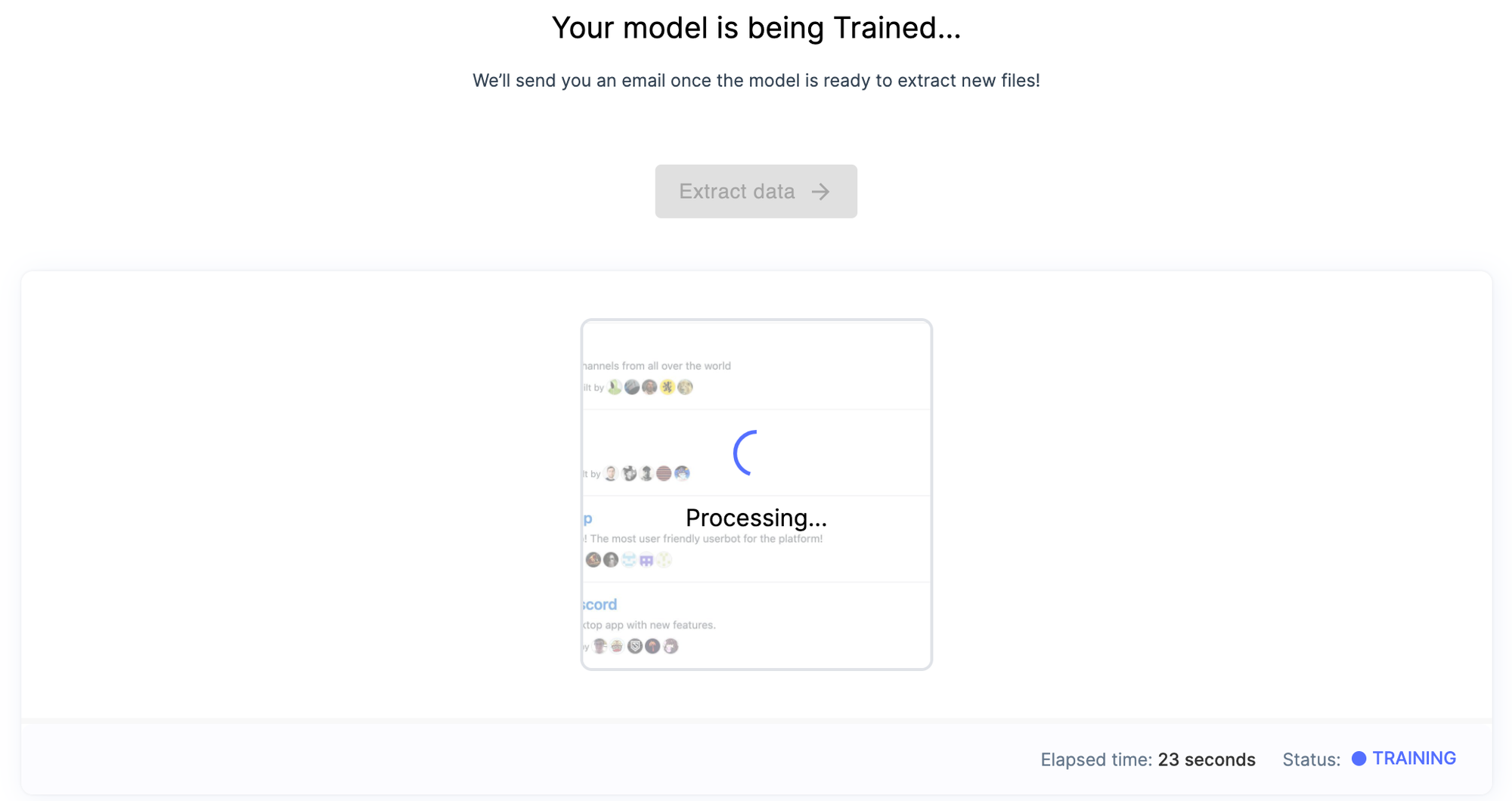
模型测试
Mindee 的测试功能只能说是一个 web demo,肉眼看看模型的效果,而 Nanonets 的测试界面功能就相当丰富了:
- 测试文件管理:可以查看、过滤所有历史文件
- 外部集成:模型抽取的结果可以集成数据库、webhook 等,提升了集成的便利程度
- 抽取结果修正(坐标框 + 识别结果)以及标记确认:经过人工确认的图片可以直接用于重新训练模型
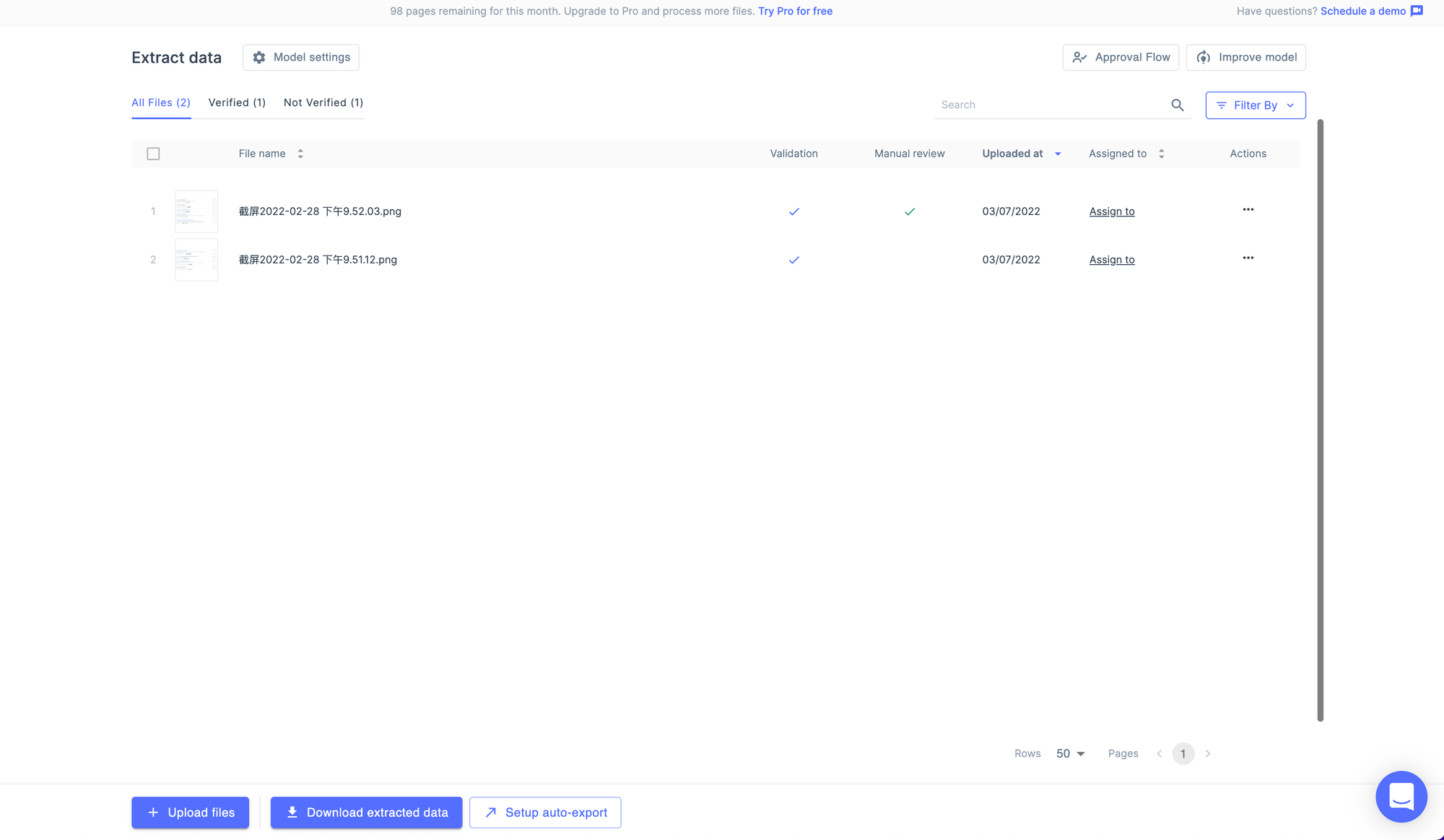
逐一确认每个字段是否正确,这个阶段可以修改检测框的坐标和框内的识别内容
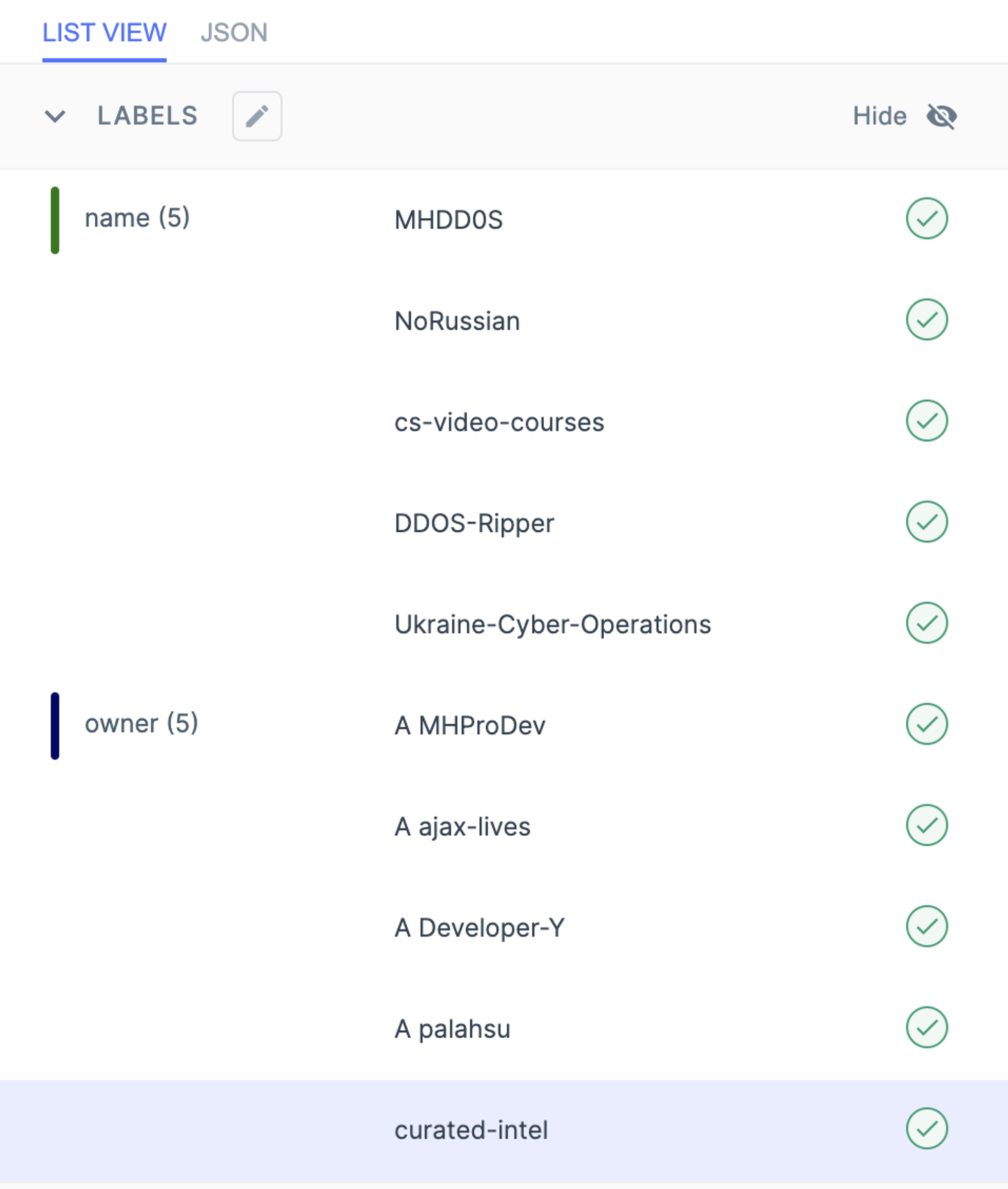
唯一“不足”的地方是没有测试集的概念,看不到模型的性能指标,作为算法工程师看不到性能指标总感觉有点虚。
owner 字段的提取结果和标注时一样,前面都带了一个大写字母 A,利用前面提到的 python 脚本很方便地就把这个前缀去掉了。
总结
Nanonets 总的来说感觉比 Mindee 和百度 EasyDL OCR 的完成度都高很多(除了糟心的标注体验),特别是灵活的后处理以及方便的数据回流,能够大大提高其实用性。